
来源:科诺科研

做非小细胞肺癌(NSCLC)研究时,是不是总愁 “多组学怎么整合才不像‘数据拼盘’”?“生信结果怎么结合临床样本落地”?空军军医大唐都医院团队这篇刚发在Translational Lung Cancer Research(TLCR,IF=3.5) (2025 年 8 月在线)的研究,直接给答案 —— 以 “免疫原性细胞死亡(ICD)” 为核心,左手抓 “多组学 + 101 种机器学习” 建预后签名,右手补 “单细胞验证 + qRT-PCR/IHC 实验”,最后用 nomogram 落地临床,把 “临床痛点 - 生信分析 - 实验验证 - 治疗指导” 串成闭环,堪称医生发多组学文章的 “模板级操作”!
文章信息速览
原标题:The role of immunogenic cell death in the prognosis and development of treatment strategies for non-small cell lung cancer: a multiomics and machine learning approach for predictive and personalized treatment
期刊:Translational Lung Cancer Research(IF=3.5)
关键词:免疫原性细胞死亡(ICD)、非小细胞肺癌(NSCLC)、多组学、机器学习、ICDRS 预后签名、单细胞转录组、qRT-PCR 验证、免疫组化(IHC)
研究目的:
NSCLC 发病率、死亡率居高不下,且患者对免疫检查点抑制剂(ICIs)响应差异大,传统预后指标(如 TNM 分期)无法精准预测疗效和生存 —— 这正是临床医生每天面临的难题。因此团队聚焦 “ICD”(能激活抗肿瘤免疫的细胞死亡方式),想通过多组学 + 机器学习构建ICD 相关预后签名(ICDRS),解决 “NSCLC 预后难测、治疗难选” 的核心痛点。
研究亮点:
医生做多组学,不是比“谁分析的维度多”,而是比 “谁的结果更贴近临床”。这篇文章的 4 个亮点,每步都踩在期刊偏好上:
1. 用 WGCNA “精准筛基因”,拒绝 “无差别堆数据”(图 1)
做多组学的第一步,是找到“真和临床相关” 的基因,而不是盲目筛差异基因。团队先对 TCGA 的 NSCLC 数据做分层:
按疾病阶段把患者分成 11 个集群,免疫注释为 “上皮、免疫、基质”3 类细胞群(图 1A-B),再用 marker 基因标注出 9 种细胞类型(B 细胞、DC 细胞、巨噬细胞等,图 1C);
通过 AUC 评分发现,单核细胞和巨噬细胞与 ICD 关联最强(评分最高,图 1E),直接锁定核心细胞类型;
用 WGCNA 构建基因共表达网络,选 β=7 满足无标度拓扑(图 1F),通过高维 WGCNA(hdWGCNA)得到 8 个基因模块,最终筛选出 “红、棕模块” 中与 ICD 高度相关的基因(P<0.001,r>0.5,图 1H)。
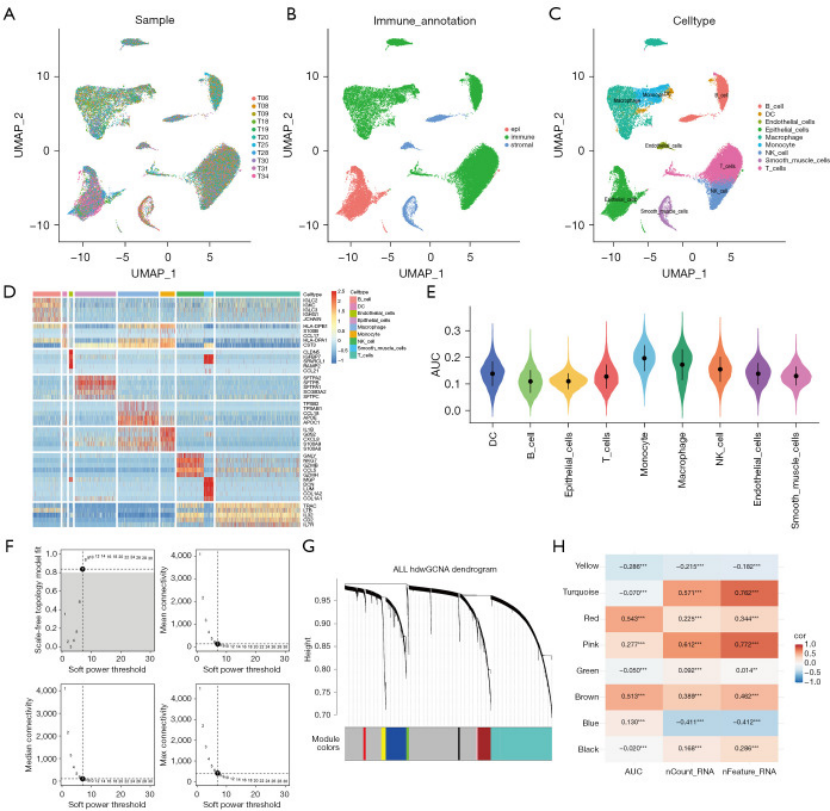
图1
筛基因要“锚定临床表型”(这里是 ICD 和 NSCLC 预后),WGCNA 比单纯的差异分析更能找到 “共调控的功能模块”,后续建模也更有生物学意义。
2. 101 种机器学习 “少而精”,多队列验证是关键(图 2)
很多人做机器学习爱堆算法,但医生发文更看重“结果稳定、能复用”。团队从第一步筛选的 29 个 ICD 相关 NSCLC 基因出发:
用 10 种经典算法(Lasso、Ridge、随机生存森林等),搭配 10 折交叉验证,做出 101 种算法组合;
在 5 个队列(训练集、测试集、GSE13213、GSE31210、GSE72094)中验证,发现Lasso+StepCox 组合的 C-index 最高(0.631,图 2A) ,稳定性最好;
最终锁定 5 个关键基因(MMP14、ALDH2、FBP1、HLA-DRA、KCTD12),构建的 ICDRS 在训练集 1 年、3 年、5 年 AUC 分别达 0.735、0.713、0.649(图 2B),KM 曲线显示 “低危组患者生存显著优于高危组”(P<0.001,图 2C)。
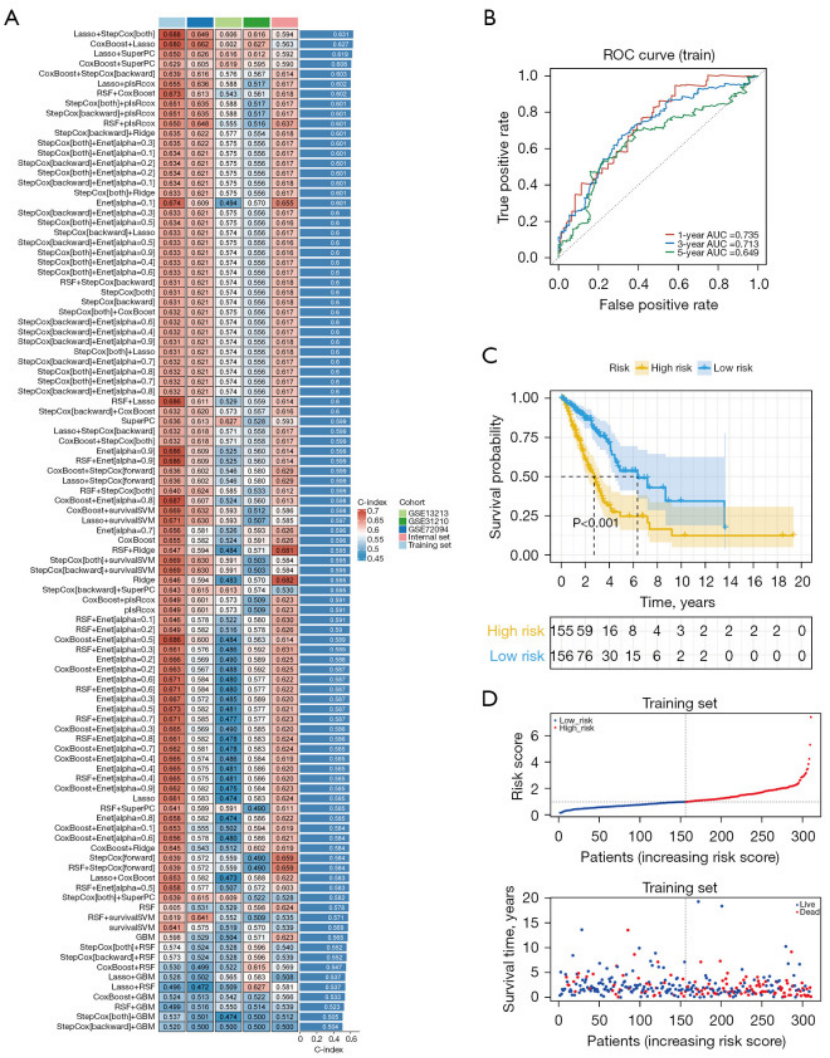
图2
从此可见该研究不侧重去寻找 “冷门算法”,使用常用算法 + 多队列验证更显严谨;AUC、C-index 这些指标要 “硬”,毕竟临床医生看的是 “能不能用”,而不是 “算法多花哨”。
3. 用 nomogram 落地临床,把 “签名” 变成 “工具”(图 3)
多组学文章想加分,必须回答“这个结果对临床有什么用”。团队做了关键一步 —— 把 ICDRS 和临床指标结合:
单因素 Cox 分析发现,ICDRS、T 分期、N 分期、M 分期都是预后因素(HR>1.5,P<0.001);但多因素分析后,只有 ICDRS 是独立预后因素(HR=1.690,95% CI:1.397-2.044,P<0.001,图 3A-B);
基于 ICDRS 和年龄、性别、TNM 分期,构建了 “nomogram 预后模型”(图 3C),能直接帮医生预测患者 1-10 年的总生存期(OS);
验证显示,这个 nomogram 的 C-index 比单独用 “性别、年龄” 等临床指标更高(图 3D),校准曲线也证明 “预测值和实际生存情况高度吻合”(图 3E)。
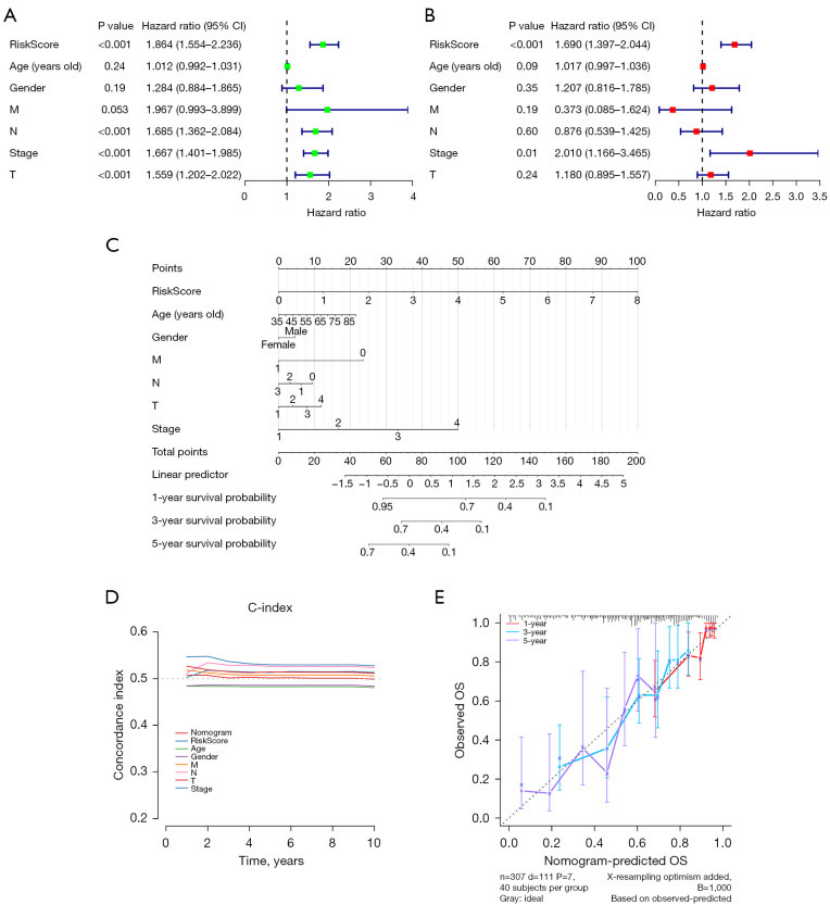
图3
单纯的“风险评分” 对临床来说太抽象,nomogram 能把 “基因表达” 转化为 “具体的生存概率”,医生拿过来就能用,期刊自然更认可这种 “有转化价值” 的设计。
4. 补实验 + 单细胞,让生信结果 “不飘”(图 4)
纯生信文章容易被质疑“结果没实锤”,医生发文一定要加 “实验验证” 这步。团队做了两件事:
单细胞水平验证:在单细胞数据中看 5 个关键基因的表达 ——ALDH2 在巨噬细胞和上皮细胞高表达,HLA-DRA 在 B 细胞高表达(图 4A);还对 11 个上皮细胞亚群做 CNV 分析,发现 C3 亚群 CNV 评分最高(图 4C),且高危组的 “糖酵解、有丝分裂纺锤体” 通路更活跃(图 4D),从单细胞层面解释了 “为什么高危组预后差”;
临床样本 + 细胞系验证:用 qRT-PCR 检测 H1975、A549 等 NSCLC 细胞系,用 IHC 检测 10 例临床 NSCLC 组织(均来自唐都医院),证实 5 个关键基因的表达模式和生信结果一致。
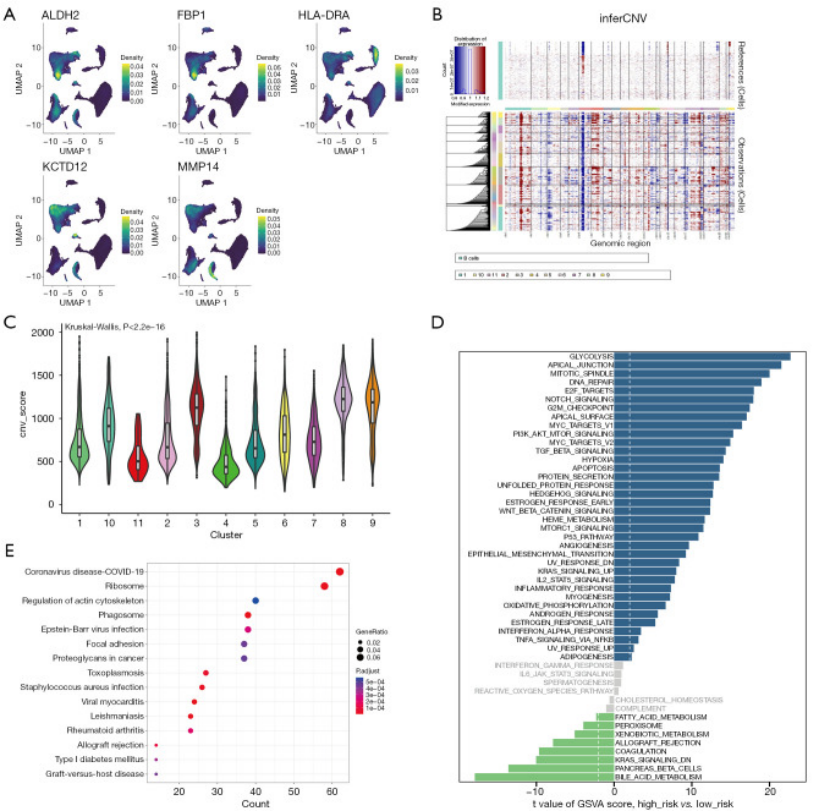
图4
从中可见,哪怕是 qRT-PCR、IHC 这种基础实验,只要结合 “自己的临床样本”,就能大幅提升文章的可信度;单细胞分析则能帮你 “挖机制”,让文章从 “纯预后” 升级为 “预后 + 机制”,深度更足。
医生发多组学文章的“3 条核心逻辑”
这篇文章虽不是“高分顶刊”,但对临床医生来说,参考价值远超某些 “纯生信炫技文”,核心逻辑有 3 条:
选题要“贴临床”:别跟风做 “泛癌多组学”,聚焦自己熟悉的疾病(如 NSCLC)+ 临床痛点(如预后、治疗响应),像这篇选 “ICD”(和免疫治疗相关),天生就有临床价值;
分析要“少而精”:多组学不是 “转录组 + 蛋白组 + 代谢组” 堆一起,而是围绕 “一个核心目标”(如构建 ICDRS)整合数据;机器学习别堆算法,多队列验证比 “算法数量” 更重要;
结果要“能落地”:一定要补实验(哪怕是小样本 IHC),最好做个 nomogram、药敏预测这类 “临床能用的工具”—— 期刊编辑和审稿人(尤其是临床背景的),更看重 “你的研究能不能帮医生解决问题”。
很多医生朋友做多组学,常卡在“公共数据挖掘”“实验设计” 或 “临床样本整合” 上 —— 别愁!我们团队能帮你从 “选题(比如结合 ICD、铁死亡等热点)”“公共数据清洗(TCGA/GEO)”,到 “qRT-PCR/IHC 实验方案设计”“临床样本关联分析” 全程对接,贴合临床医生的研究节奏,让你的多组学文章既有 “生信深度”,又有 “临床温度”,轻松拿下 3 + 甚至更高分期刊!
专注期刊投稿、发表十年,任何投稿、写作难题欢迎咨询!

PAPER INFORMATION

快速预审、投刊前指导、专业学术评审,对文章进行评价

校对编辑、深度润色,让稿 件符合学术规范,格式体例等标准
.png)
适用于语句和结构尚需完善和调整的中文文章,确保稿件达到要求
.png)
数据库包括: 期刊、文书籍、会议、预印章、书、百科全书和摘要等
让作者在期刊选择时避免走弯路,缩短稿件被接收的周期
根据目标期刊格式要求对作者文章进行全面的格式修改和调整
帮助作者将稿件提交至目标期刊投稿系统,降低退稿或拒稿率
按照您提供的稿件内容,指导完成投稿附信(cover letter)







北京总部:北京市海淀区碧桐园 3 号楼 2 层 211 广州办事处:广州市黄埔区科学城国际企业孵化器 E栋306 联系人:客服 / 18163670350
Copyright © 2022-2024 北京特诺科技有限公司 版权所有 备案/许可证编号为: 京 ICP 备 2023007944 号
