
来源:科诺科研
各位骨科、内分泌科的医生朋友,是不是总被骨质疏松的研究绊住?临床诊断靠 DXA 测骨密度,却抓不住背后的生物机制;想做组学研究,又怕数据堆得满,逻辑串不起来?别急!这篇 2025 年 8 月的SCI 文章,直接给你答案 —— 以 “内质网应激(ERS)” 为核心,左手整合 3 个 GEO 数据集筛基因,右手用 LASSO+SVM 建诊断模型(AUC 超 0.9),最后靠 OVX 小鼠实验实锤,还挖了 TF/miRNA/ 药物调控网络,把 “临床痛点 - 生信分析 - 实验验证 - 治疗靶点” 全打通,堪称医生发多组学的 “模板级操作”!要是你也卡在 “找数据、做分析、设计实验” 这几步,后面就能帮你省心搞定。

文章信息速览
原标题:Identification of Endoplasmic Reticulum Stress-Related Genes in Osteoporosis Pathogenesis
期刊:Molecular Imaging(IF=4.9)
关键词:内质网应激(ERS)、骨质疏松、多组学分析、7 基因诊断模型、OVX 小鼠模型、免疫浸润、LASSO 回归、SVM 算法
研究目的:
骨质疏松全球近 2 亿女性受累,每3 秒就有1 例骨折,但现有诊断靠 DXA 测骨密度,既难预测骨折风险,也没法解释 “骨流失” 的分子机制;而 ERS(内质网应激)明明和成骨 / 破骨细胞功能相关,却没人系统挖过它在骨质疏松里的作用 —— 这篇文章就瞄准这个 “缺口”,想通过多组学找到 ERS 相关关键基因,建一个 “准、能用” 的诊断模型,还顺便阐明背后的机制,给临床诊断和治疗递新工具。
研究亮点:
医生做多组学,不是比“分析维度多”,而是比 “每步都贴临床、结果能落地”。这篇文章的5 个亮点,每步都踩在SCI 期刊的偏好上:
1. 多数据集 “去噪整合”,筛基因不盲目(图 1A-D)
想让基因“靠谱”,先得让数据 “干净”。作者选了 3 个骨质疏松 GEO 数据集(GSE56815、GSE230665、GSE7429),先用水印去除批次效应(用 sva 包),再标准化(limma 包),确保数据可比;然后分两步筛基因:
先在“整合数据集” 和 “GSE7429” 里分别找差异基因(DEGs),取交集得到 381 个共差异基因(Co-DEGs,图 1C);
再和 GeneCards 数据库的 ERS 相关基因(ERSRGs)取交集,最终得到56 个 ERS 相关差异基因(ERSRDEGs,图 1D)—— 不是乱筛的 “随机基因”,而是 “既和 ERS 相关,又在骨质疏松里有差异” 的核心基因,后续分析才有意义。
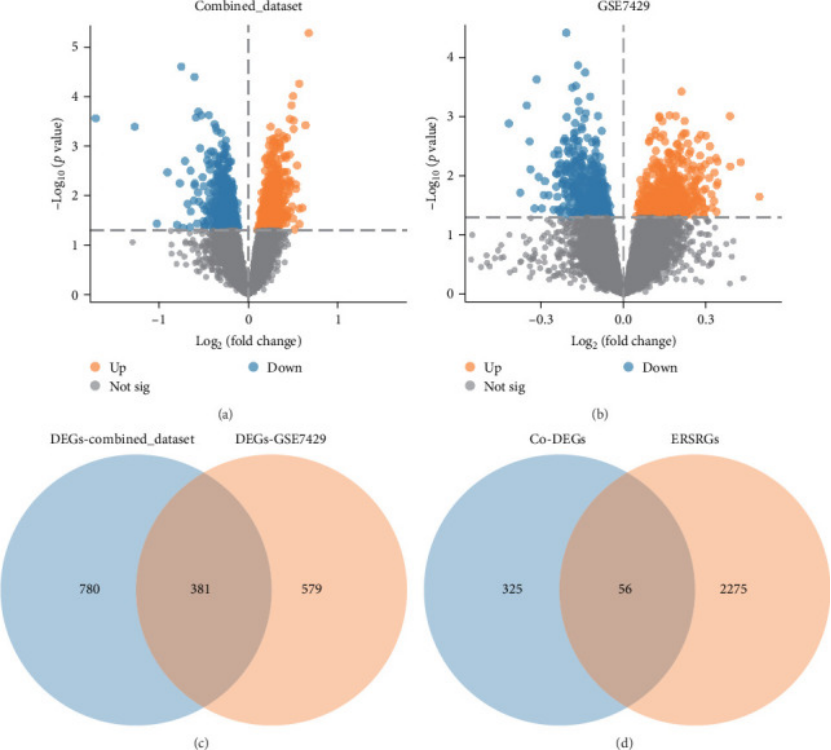
图1
2. LASSO+SVM “双算法锁基因”,模型准到 AUC>0.9(图 2H)
建诊断模型最怕“过拟合、不准”,这篇文章的做法特别严谨:
先从 56 个 ERSRDEGs 里,用 logistic 回归初筛出 13 个有统计意义的基因(p<0.1,图 2A);
再用 SVM 算法找 “最高 accuracy” 的基因组合(图 2D-E),用 LASSO 回归压维度、防过拟合(图 2F-G),最后两个算法取交集,锁定7 个核心基因(CYB5R4、RAB1B、UFSP2、RNF13、SERP1、CES2、C1QBP,图 2H) ;
用这 7 个基因建模型,在训练集、验证集(GSE7429)的 AUC 全超 0.9(图 S4C-D),还做了 nomogram 把 “基因表达” 转成 “可视化预后评分”,用 DCA 验证 “临床净获益高”—— 医生拿到就能用,期刊当然喜欢这种 “落地性强” 的模型。
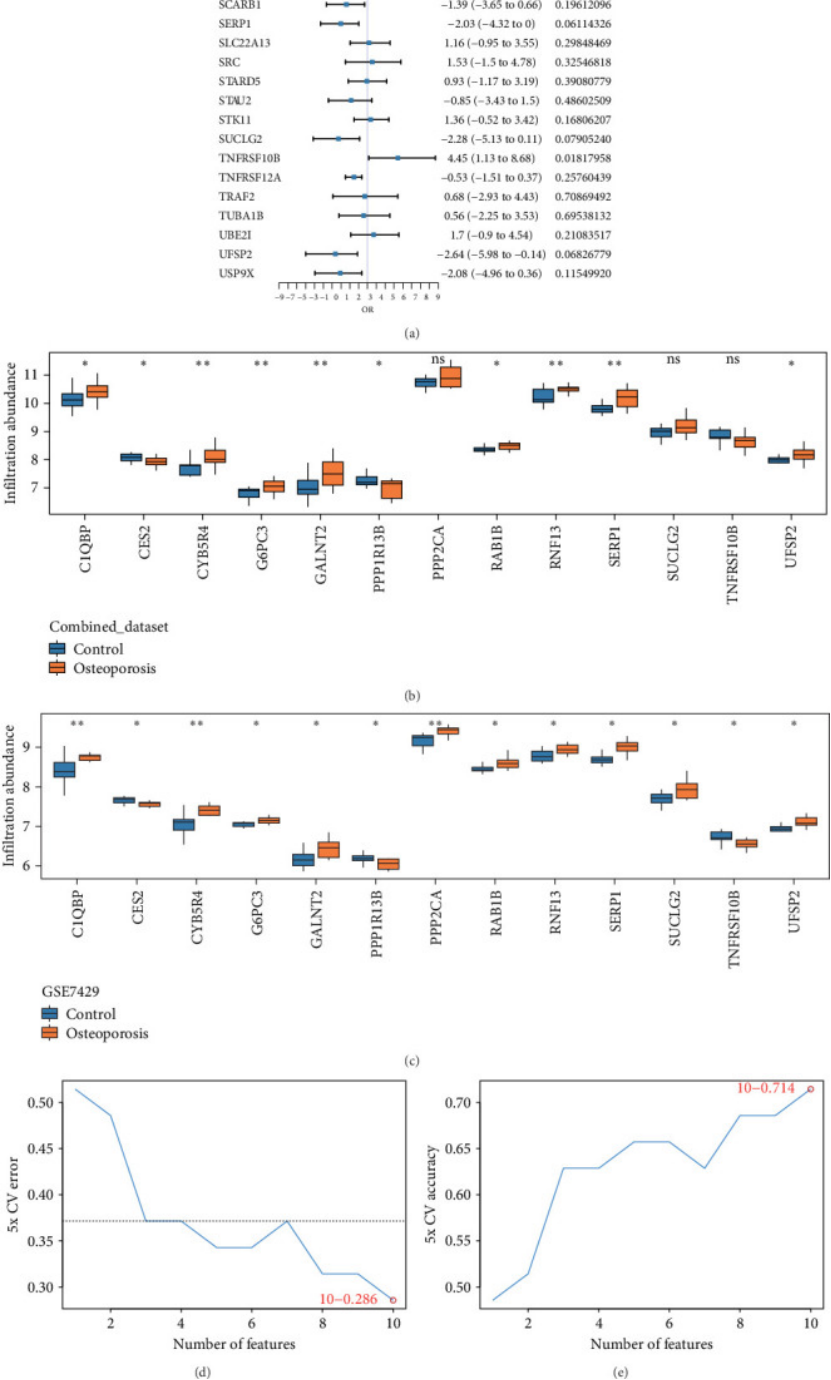
图2
3. 免疫浸润 “分高低危”,挖机制不只是 “建模型”(图 3A、图 4B)
多组学不能只停留在“诊断”,还要说清 “为什么高危组预后差”。作者把患者按模型风险分 “高 / 低危”,用 ssGSEA 和 CIBERSORT 分析免疫细胞:
发现高危组的活化 B 细胞、活化 CD8+T 细胞更多(图 3A),这些细胞可能促进炎症,加重骨流失;
CIBERSORT 还发现,高 / 低危组在 M0 巨噬细胞、活化 NK 细胞、静息 CD4 + 记忆 T 细胞上差异显著(p<0.05,图 4B) —— 相当于解释了 “7 基因模型区分风险” 的生物学原因,文章深度一下就上来了。
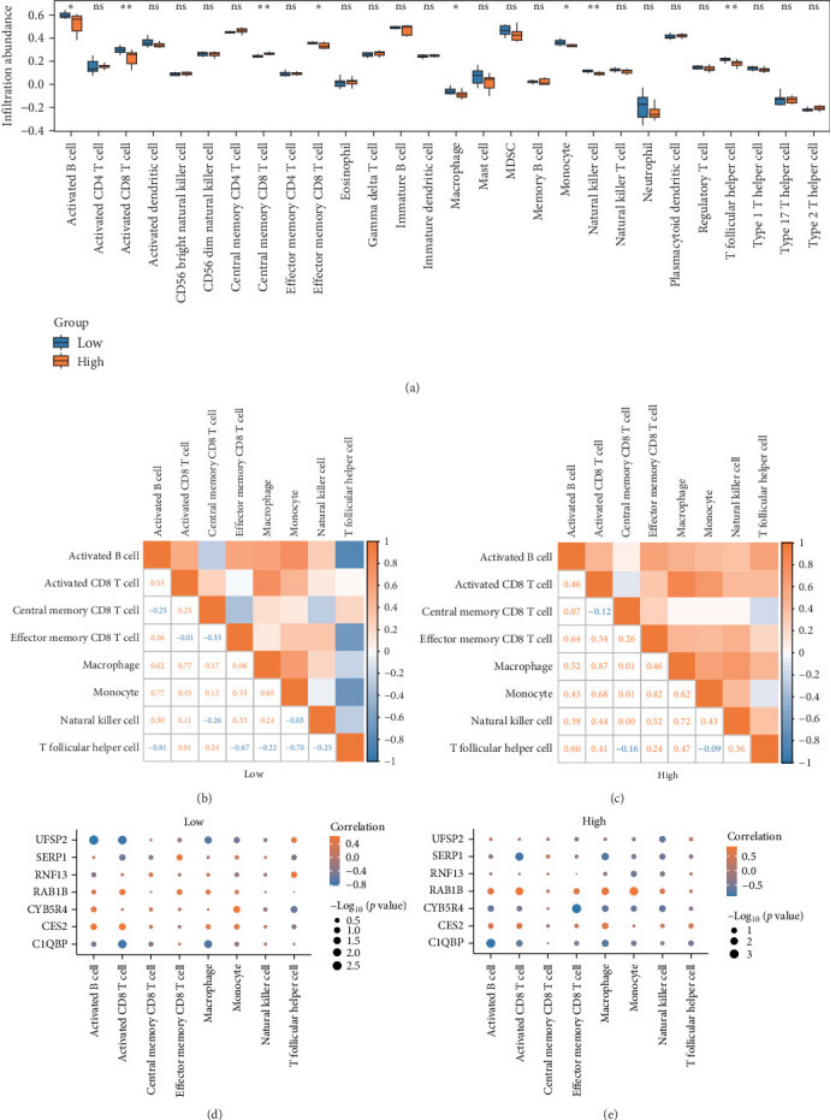
图3
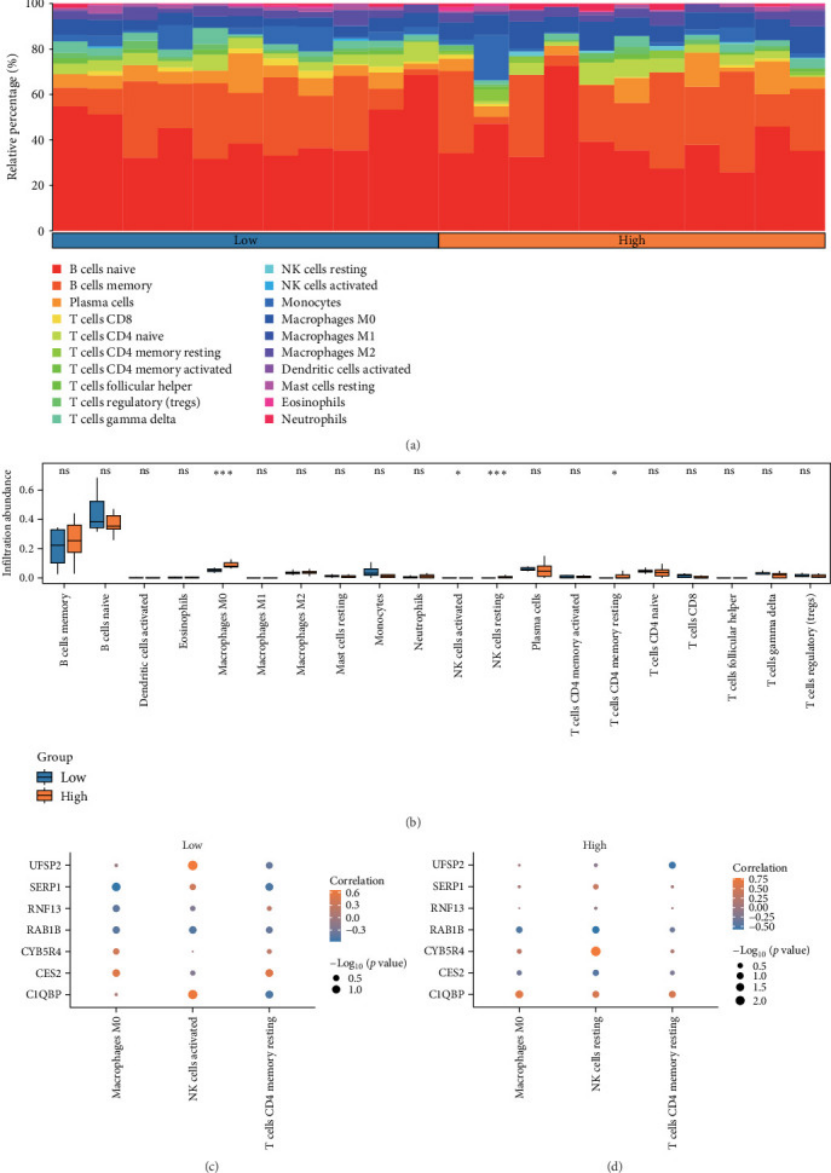
图4
4. OVX 小鼠 “实锤验证”,生信结果不 “飘”(图 5A-C)
纯生信文章容易被质疑“没实验支撑”,这篇文章直接上动物实验:
做了 OVX 小鼠模型(模拟绝经后骨质疏松),用 IHC 测 7 个基因的蛋白表达,发现C1QBP、CYB5R4、RAB1B、UFSP2 的蛋白水平在 OVX 组显著升高(p<0.01,图 5A-B) ;
用 qRT-PCR 测 mRNA,结果和蛋白一致(图 5C)—— 生信预测的 “基因高表达”,在动物模型里真能测到,可信度直接拉满,这也是 SCI 期刊很看重的 “干湿结合”。
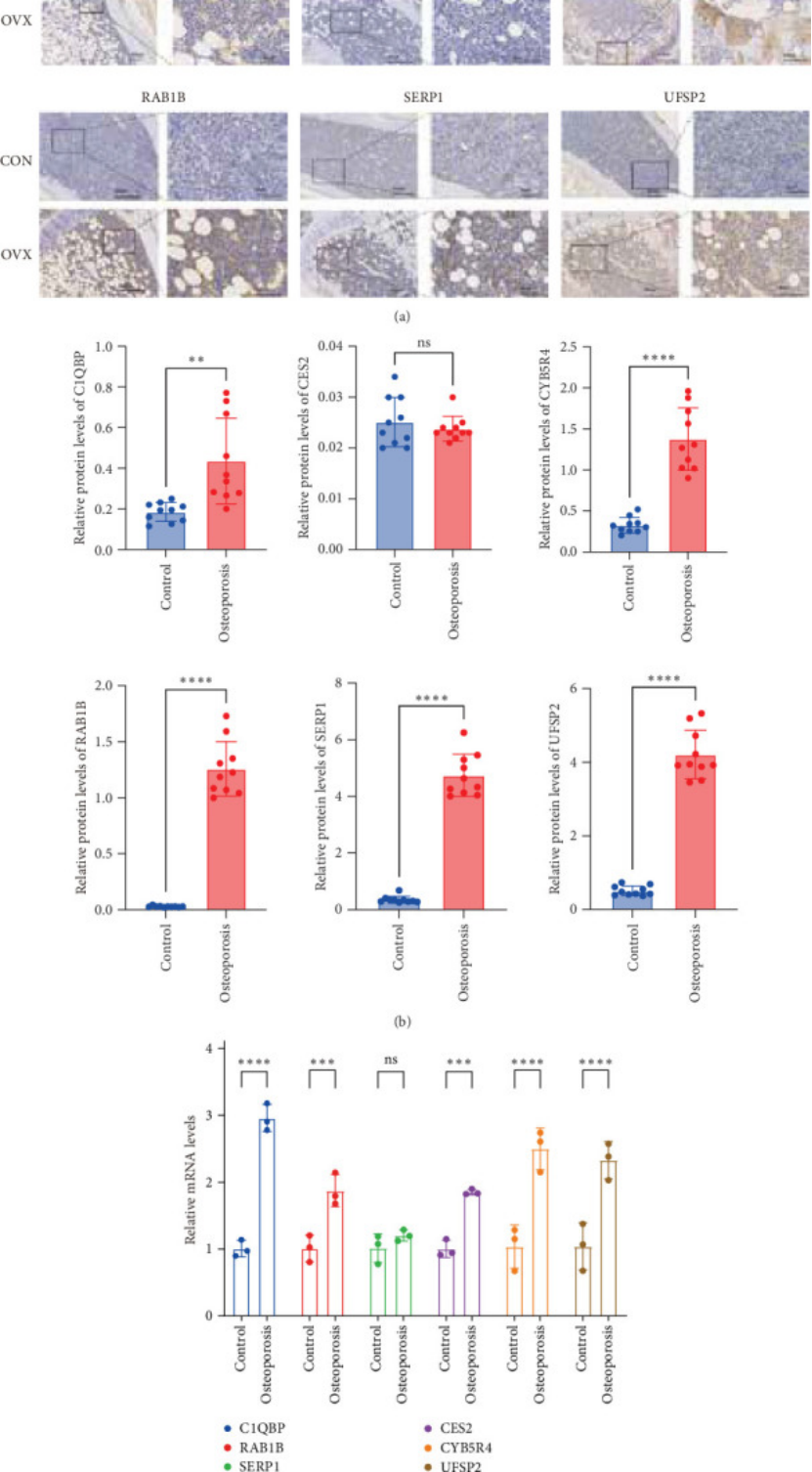
图5
5. 调控网络 “挖靶点”,给治疗留口子(图 6A-D)
好的研究还要“有后续价值”,作者没停在 “诊断”,还建了 4 大调控网络:
mRNA-TF 网络(52 个 TF,图 8A)、mRNA-miRNA 网络(42 个 miRNA,图 6C)、mRNA-RBP 网络(32 个 RBP,图 6D),还有 mRNA - 药物网络(27 种潜在药物,图 6B)—— 比如找到能调控这些基因的药物,未来可能开发成治疗靶点,文章的 “转化价值” 一下就高了。
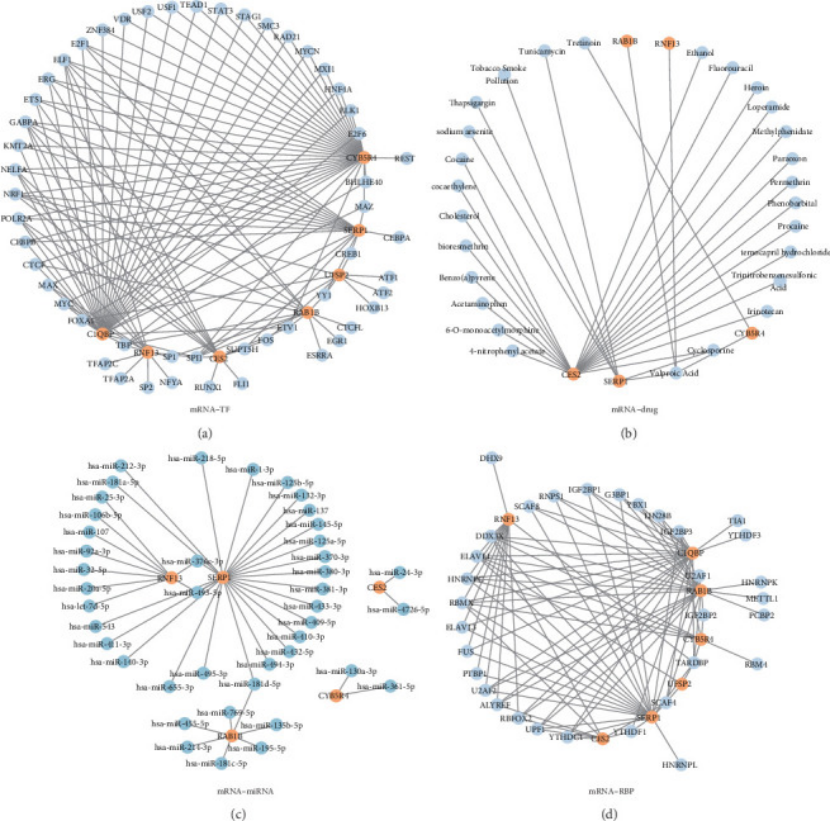
图6
这篇文章虽不是“顶刊高分”,但对临床医生来说,参考价值远超 “炫技的纯生信文”,核心逻辑就 4 条:
选自己熟悉的疾病(比如骨质疏松)+ 临床痛点(比如诊断不准、机制不清),结合 ERS 这种 “有研究基础但没挖透” 的方向,选题天生就有优势;
数据要“严谨去噪”,多数据集整合一定要去批次效应,筛基因要“多步交集”,避免 “假阳性基因” 毁了后续分析;
模型要“临床能用”,别只报 AUC,做 nomogram、DCA,把复杂的基因数据转成医生能懂的 “评分表”,落地性强才受期刊欢迎;
实验要补充实证,哪怕只是小样本的动物实验(比如 OVX 小鼠)、qRT-PCR/IHC,只要能验证生信结果,就能大幅提升文章可信度。
原文DOI: 10.1155/mi/6726771
专注期刊投稿、发表十年,任何投稿、写作难题欢迎咨询!

PAPER INFORMATION

快速预审、投刊前指导、专业学术评审,对文章进行评价

校对编辑、深度润色,让稿 件符合学术规范,格式体例等标准
.png)
适用于语句和结构尚需完善和调整的中文文章,确保稿件达到要求
.png)
数据库包括: 期刊、文书籍、会议、预印章、书、百科全书和摘要等
让作者在期刊选择时避免走弯路,缩短稿件被接收的周期
根据目标期刊格式要求对作者文章进行全面的格式修改和调整
帮助作者将稿件提交至目标期刊投稿系统,降低退稿或拒稿率
按照您提供的稿件内容,指导完成投稿附信(cover letter)







北京总部:北京市海淀区碧桐园 3 号楼 2 层 211 广州办事处:广州市黄埔区科学城国际企业孵化器 E栋306 联系人:客服 / 18163670350
Copyright © 2022-2024 北京特诺科技有限公司 版权所有 备案/许可证编号为: 京 ICP 备 2023007944 号
