
来源:特诺科研
各位肾内科、泌尿外科医生朋友,是否觉得“肾缺血再灌注损伤(IRI)” 相关研究难出创新?要么怕实验多、要么怕机制浅?今天就带大家拆解北京朝阳医院团队的这篇 IRI 多组学研究,从公共数据挖到小鼠验证,每步都踩在 “临床转化” 上 —— 要是你觉得自己梳理数据、设计模型麻烦,找我们团队帮你搞定从数据筛选到图表生成的全流程,省心出成果!

一、文章信息速览
原标题:Identifying Immuno-Fibrotic Roles of Lactylation-Related T Cell Hub Genes in Renal Ischemia–Reperfusion Injury: A Multi-Omics Study and Experimental Validation
期刊:Journal of Inflammation Research(IF=4.1)
关键词:肾缺血再灌注损伤(IRI)、乳酸化、T 细胞、枢纽基因(HLA-E/IGHM/CORO1A/TUBA1A)、多组学分析(scRNA-seq/hdWGCNA)、机器学习、分子对接、肾移植纤维化
二、拆解论文“行文架构”:适配肾病领域的多组学发文逻辑
这篇文章能成,核心是走了“找‘代谢 - 免疫’核心细胞→筛枢纽基因→建预测模型→药物 + 实验验证” 的闭环,没堆砌方法,全程围绕 “IRI 后乳酸化 T 细胞怎么促纤维化” 展开,精准契合肾病领域对 “临床问题 + 机制落地” 的要求,咱们医生做研究也能照这个模板抄!
1. 公共库+ 小样本结合,降低成本还贴临床
作者没做大规模测序,而是先挖GEO 公共数据(scRNA-seq 数据集 GSE180420,含 18 只小鼠 IRI 样本;4 个芯片数据集 GSE53605/GSE76882/GSE22459/GSE21374,含人肾移植纤维化样本),再补充自己的小鼠单侧 IRI 模型(8 周龄 C57BL/6,仅做 1/7/14 天取样,实验量小)。
关键操作:专门聚焦“乳酸化相关基因(LRGs)”(332 个,含 “Writer/Eraser” 酶),用 AUCell/GSVA 算乳酸化评分,直接锁定 “高乳酸化细胞”—— 这步超关键,避免后续分析 “无的放矢”,医生做研究也得先找 “核心靶点”(对应图 1A-E,IRI 后尤其是长缺血组乳酸化评分显著升高,T cell_2 集群评分最高)。
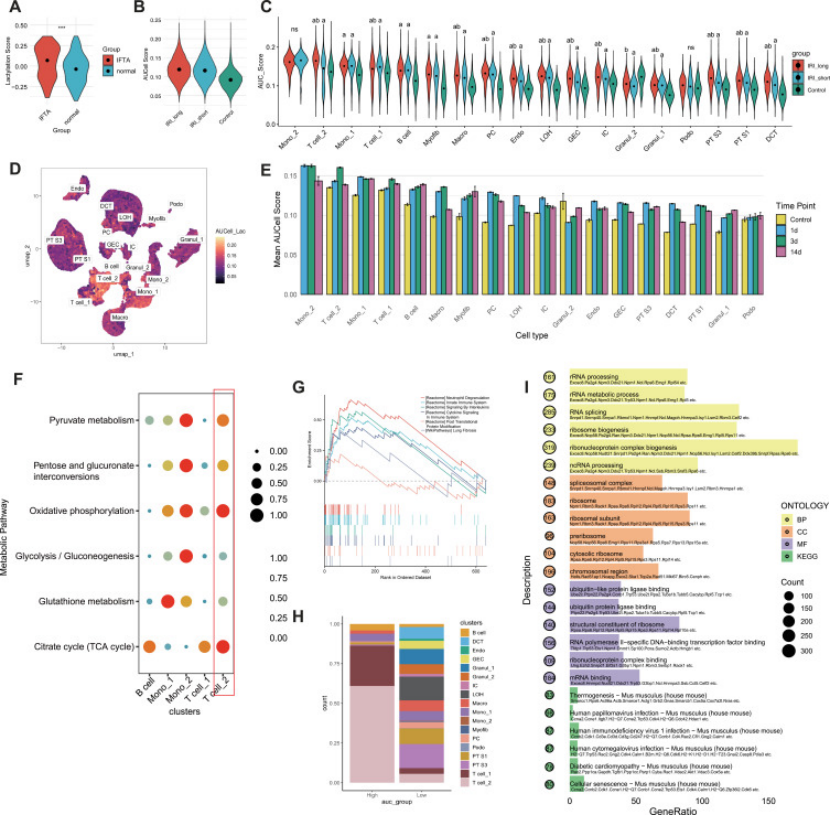
图1
2. 抓 T cell_2 集群,聚焦 “乳酸化 + 免疫” 交叉点
IRI 涉及多种细胞,作者没泛泛分析,而是通过 scRNA-seq + 代谢活性分析(scMetabolism 包),发现T cell_2 集群是 “乳酸化高 + 代谢重编程(糖酵解 / TCA 循环活跃)+ 促纤维化” 的核心(图 1F-G):
还做了细胞通讯分析(CellChat),发现 T cell_2 和单核细胞互动增强,尤其 MIF-(CD74+CD44) 信号轴激活(图 2A-C)—— 这步直接把 “细胞” 和 “纤维化机制” 挂钩,比单纯分析细胞比例更有深度,审稿人一看就觉得 “有临床意义”。
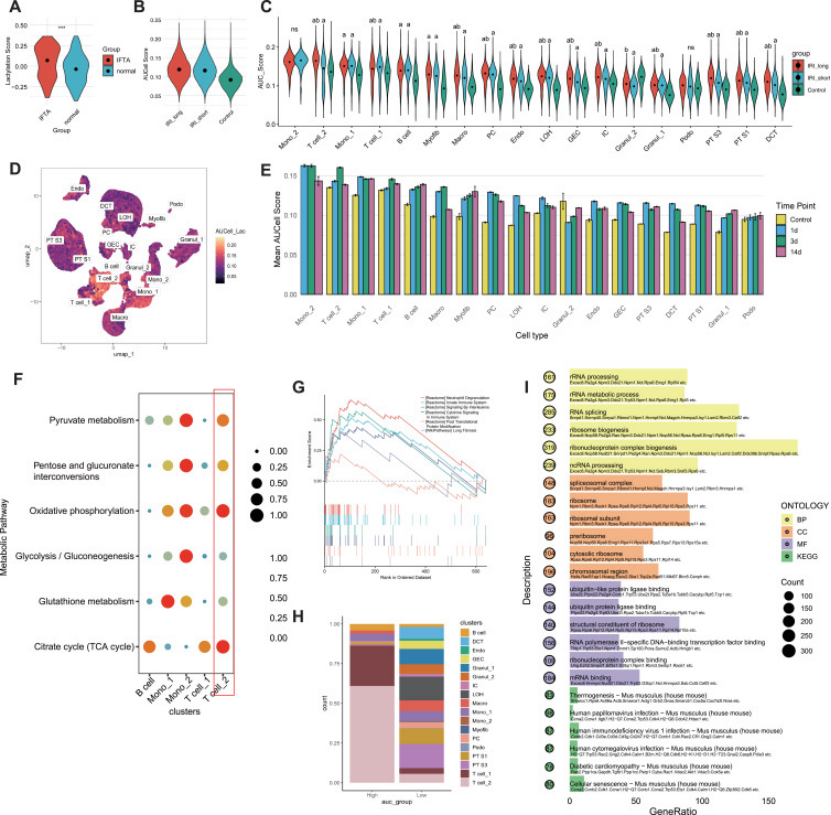
图2
3. 筛枢纽基因 ——hdWGCNA + 机器学习,结果经得起推敲
选基因没靠单一方法,而是用“hdWGCNA(单细胞加权共表达网络)+8 种机器学习” 交叉验证:
先用 hdWGCNA 对 T cell_2 集群建网络,选到 3 个和 “乳酸化 + 长缺血” 强相关的模块(M2/M4/M6),再和芯片数据的纤维化差异基因交集,得到 38 个候选基因(图 2D-K);
然后用 8 种机器学习(随机森林、SVM 等)筛选,最终锁定 4 个枢纽基因(HLA-E/IGHM/CORO1A/TUBA1A)—— 随机森林模型最优,训练集 AUC=0.888,测试集 AUC=0.897(图 3A-B),这种 “多方法交叉” 十分严谨。
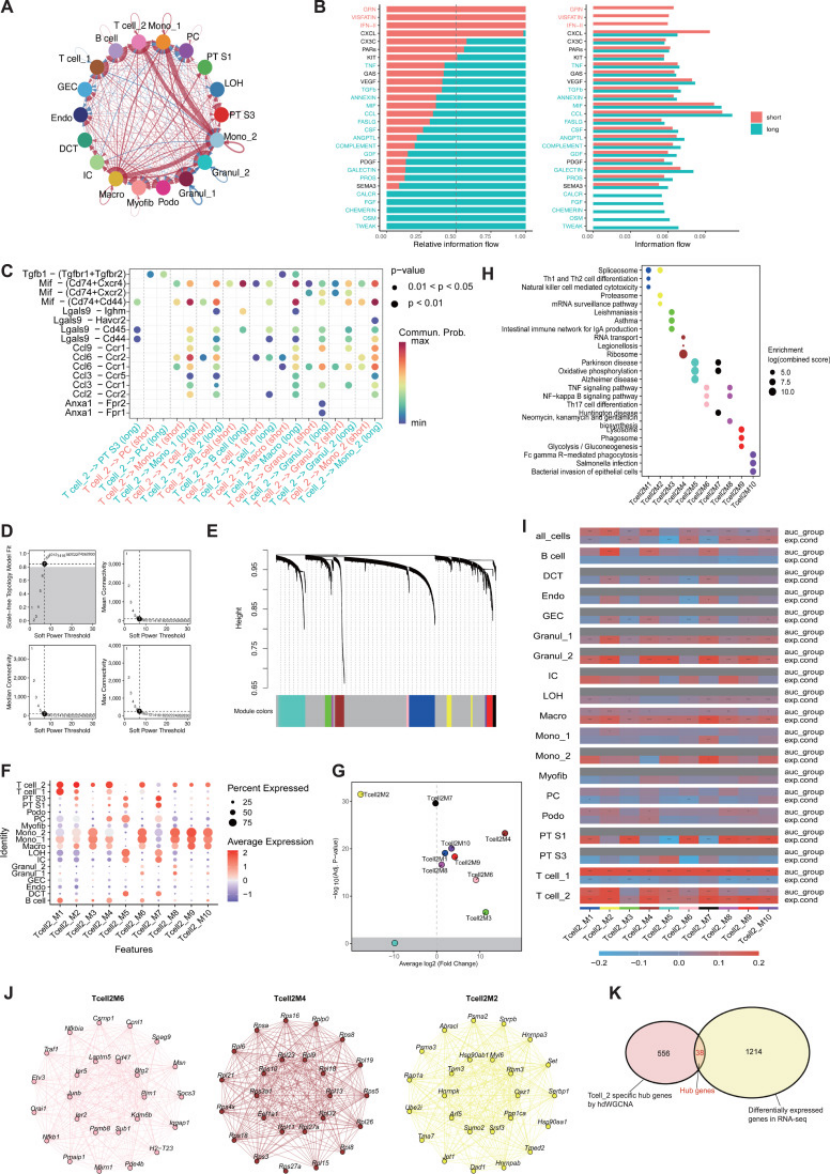
图4
4. 建 “预后模型”—— 关联临床指标,提升文章价值
肾病领域超看重“临床转化”,作者用 4 个枢纽基因建了乳酸化风险评分(公式:风险评分 = 1.568TUBA1A -1.921CORO1A +3.458HLA-E +0.504IGHM):
这个评分能精准预测肾移植预后:1/2/3 年移植肾存活 AUC 分别达 0.83/0.86/0.87(图 5H-I),还和临床指标强关联(CORO1A/HLA-E/IGHM 高表达→GFR 降、Scr 升,图 6A-F)—— 这步直接把 “基础机制” 和 “医生关心的临床结局” 绑定,文章实用性瞬间拉满。
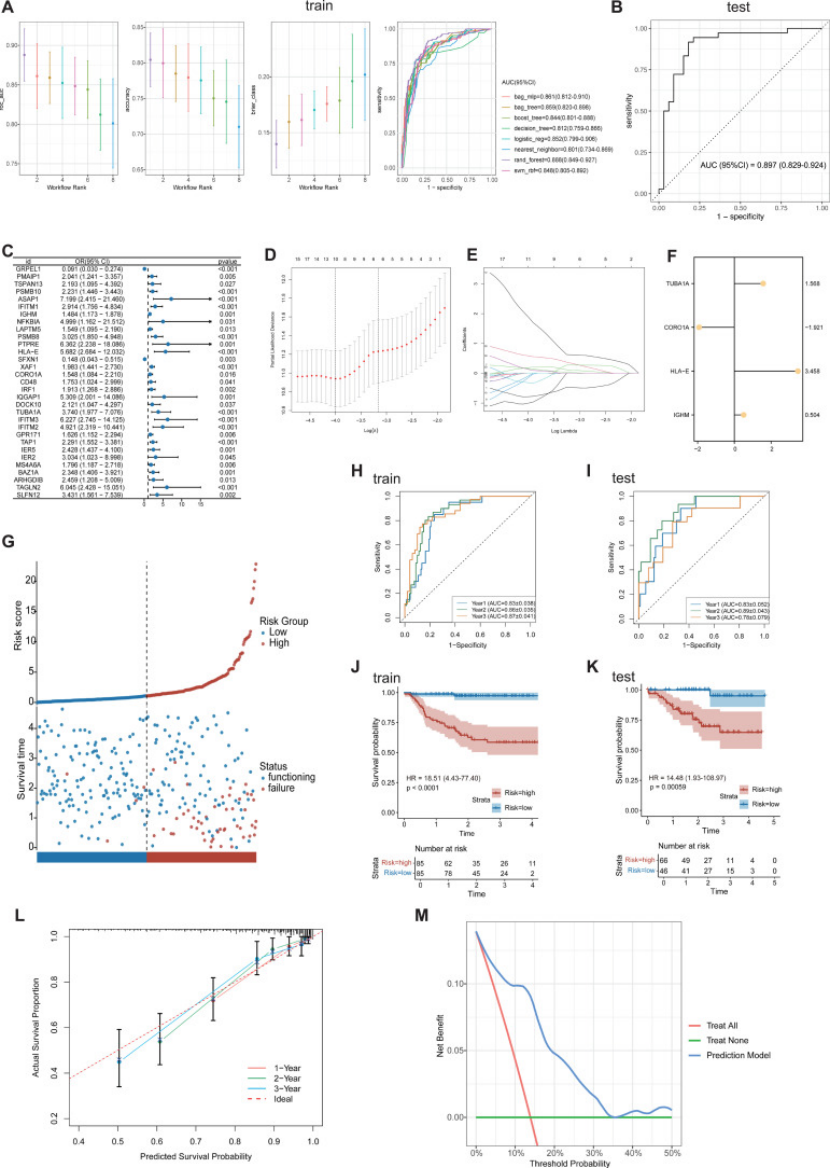
图5
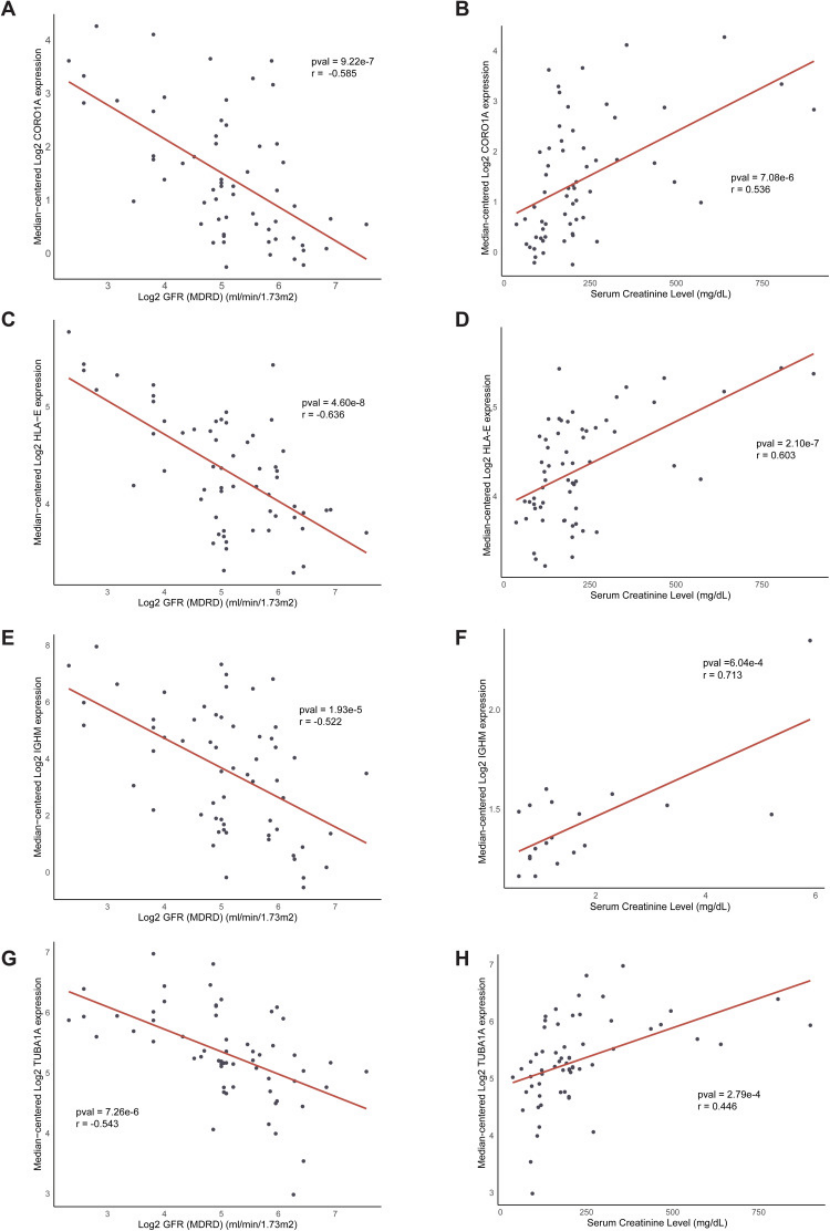
图6
5. 第五步:药物 + 实验验证 —— 少而精,支撑结论不费力
怕生信结果飘?作者做了两件“轻量级” 验证,性价比超高:
药物预测 + 分子对接:用 CellMiner 找靶点药,比如 HLA-E 对 PLX-4720( vemurafenib 类似物)结合能达 - 9.4 kcal/mol,CORO1A 对 ST-3595 结合能 - 8.1 kcal/mol(图 7A-F)—— 不用做实验,靠计算就能提 “治疗潜力”;
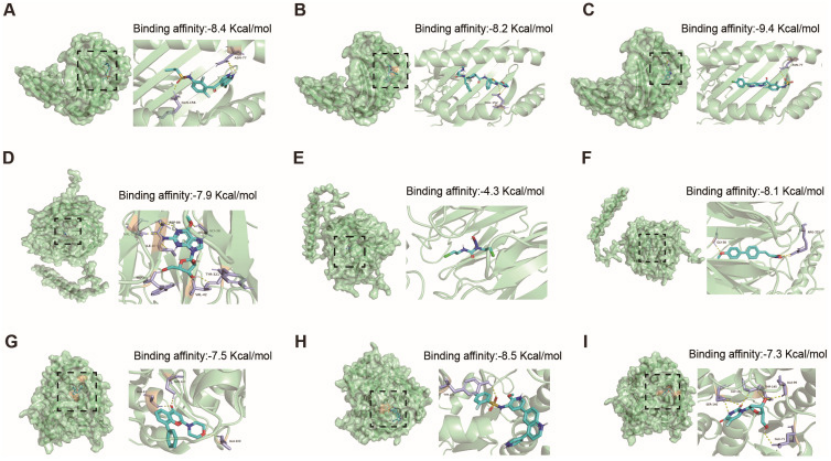
图7
小鼠实验验证:仅做 qPCR 和染色,就证实 4 个枢纽基因在 IRI 小鼠肾组织中高表达(图 10C),H&E/Masson 染色也验证了纤维化(图 8A)—— 医生不用做复杂细胞实验,补个动物模型的 qPCR/IHC 就能落地。
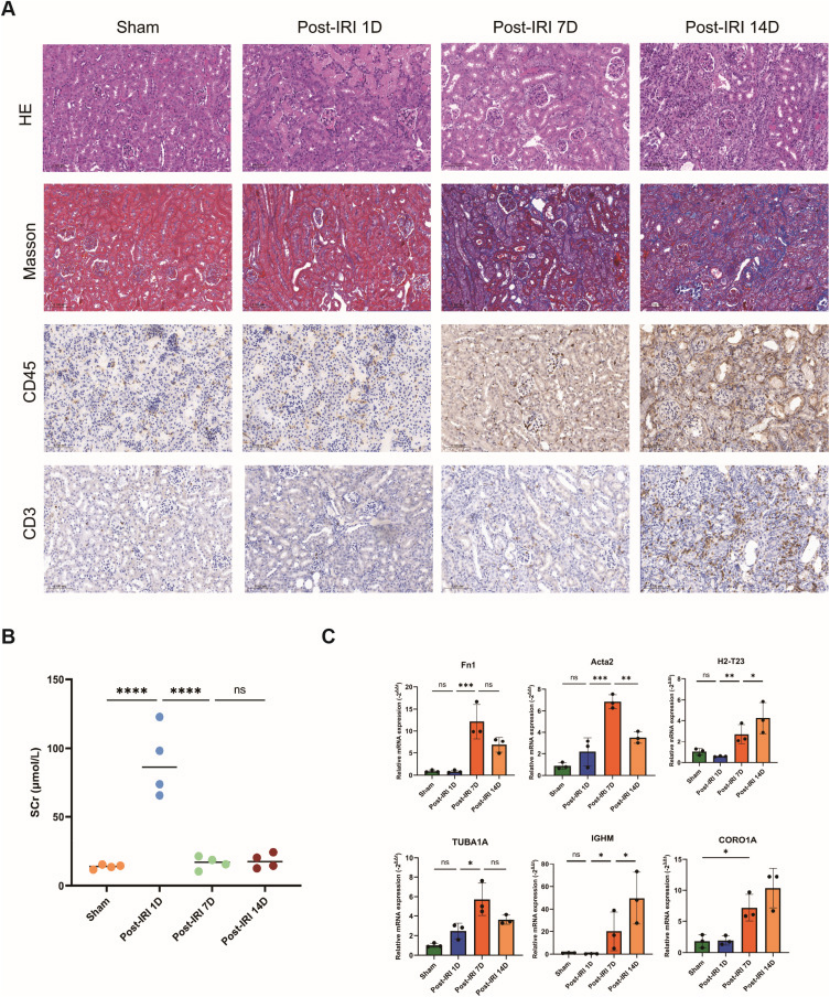
图8
三、发文技巧与启示
抓“代谢 - 免疫 - 纤维化” 交叉热点:IRI 的核心是 “缺血→代谢乱(乳酸堆积)→免疫激活→纤维化”,作者紧扣这个链条,从乳酸化切入 T 细胞,比单纯做 “免疫细胞浸润” 更有创新;医生可以类比,比如从 “脂质代谢”“氧化应激” 切入其他肾病(如糖尿病肾病)。
“公共数据生信 + 小样本验证” 性价比最高:用 GEO 的 scRNA-seq / 芯片数据做前期挖掘,自己补 10-20 只小鼠(或少量临床样本)做 qPCR / 染色,成本低、周期短,临床忙也能做。
模型要“贴临床”:别建 “无意义的预测模型”,像作者那样关联 “移植肾存活”“GFR/Scr”,比单纯预测 “是否纤维化” 更受期刊欢迎 —— 审稿人最烦 “纯生信不落地”。
要是你想发 IRI / 肾移植相关 5+,却卡在 “找核心细胞”“建模型” 或 “实验设计” 上,直接找我们团队!从匹配热点的分析框架,到少而精的实验方案,再到图表生成,全程帮你把关,让你把临床遇到的IRI 问题快速转化成论文成果~
专注期刊投稿、发表十年,任何投稿、写作难题欢迎咨询!

PAPER INFORMATION

快速预审、投刊前指导、专业学术评审,对文章进行评价

校对编辑、深度润色,让稿 件符合学术规范,格式体例等标准
.png)
适用于语句和结构尚需完善和调整的中文文章,确保稿件达到要求
.png)
数据库包括: 期刊、文书籍、会议、预印章、书、百科全书和摘要等
让作者在期刊选择时避免走弯路,缩短稿件被接收的周期
根据目标期刊格式要求对作者文章进行全面的格式修改和调整
帮助作者将稿件提交至目标期刊投稿系统,降低退稿或拒稿率
按照您提供的稿件内容,指导完成投稿附信(cover letter)







北京总部:北京市海淀区碧桐园 3 号楼 2 层 211 广州办事处:广州市黄埔区科学城国际企业孵化器 E栋306 联系人:客服 / 18163670350
Copyright © 2022-2024 北京特诺科技有限公司 版权所有 备案/许可证编号为: 京 ICP 备 2023007944 号
