
来源:科诺科研
多组学、人工智能、药物发现,单拎出任何一个主题,都能写成一篇长综述。
通常来说,把三者塞进同一篇文章,常见结果是名词很多,主线很弱。测序技术讲一段,机器学习讲一段,再补几个药物案例,资料看着齐,读完却很难复述作者究竟回答了什么问题。
但今天要拆解的这篇论文,却写出了一些不一样的味道。
2026年,Liu等人在Signal Transduction and Targeted Therapy发表综述 Multi-omics and artificial intelligence for precision drug discovery and potential clinical applications。全文32页,配置7幅图、8张表和361篇参考文献。
这篇文章处理了一个很宽的题目,却没有完全散掉。原因很直接:作者始终沿着药物研发流程写,多组学和AI只是嵌入流程的两类工具。
如果你也准备写交叉学科综述,这篇论文可以当作结构样本。论文信息
作者没有按“基因组学、转录组学、蛋白质组学、代谢组学”依次介绍,也没有按随机森林、图神经网络、Transformer逐个讲算法。
他们先画出药物研发链条:靶点发现、药物重定位、先导化合物发现与优化、药物相互作用、安全性评价、疾病应用,最后落到临床试验。
多组学负责提供疾病和患者的分子信息,AI负责整合、预测和排序。两条技术线跟着研发任务移动,文章因此有了稳定的方向。
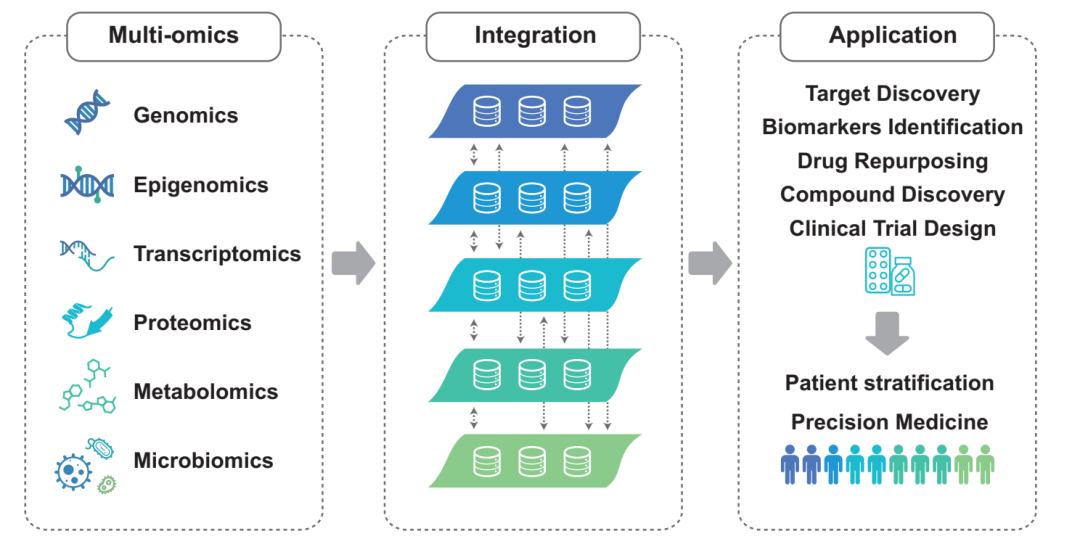
图1(原文Figure 1):作者先用一张总图划定综述边界。多组学并未停留在生物标志物发现,还被连接到药物重定位、化合物发现、临床试验设计和患者分层。
这个做法很适合宽主题综述。
动笔前先回答一句话:文章准备沿哪条过程,把所有技术和案例串起来?
对于药物研发题目,可以沿研发阶段写;对于疾病机制,可以沿“危险因素—分子改变—组织表型—临床结局”写;对于方法学论文,可以沿“数据输入—模型—验证—应用”写。
主线一旦确定,哪些内容该留、哪些只能放进表格,判断会容易很多。
这篇综述的引言并不短,但任务很明确。
开头先交代药物研发的现实压力。原文援引的数据是:临床试验淘汰率超过90%,一款最终获批药物的平均总成本约为26亿美元。
接着,作者把问题归因于传统还原论框架的局限。复杂疾病涉及基因组、表观基因组、转录组、蛋白质组和代谢组之间的联动,单靶点模型很难覆盖这种动态关系。
第三步转向工具条件。空间组学、单细胞测序、高通量蛋白质组和代谢组提供更细的观测尺度,深度学习、图神经网络和生成模型负责处理异构数据。
引言末尾才交代本文范围:多组学用于靶点发现、药物重定位和新化合物发现;AI用于虚拟筛选、药代动力学建模和安全性评价;肿瘤、神经系统疾病、心血管疾病与临床试验作为转化案例。
可以把这套引言骨架记成四个问题:
引言里最该避免的是过早堆工具名。读者还没明白问题,算法和平台就排着队出现,后文很难建立轻重。
正文第一大部分讨论多组学在药物发现中的用途,依次覆盖靶点识别、药物重定位和原创新化合物发现。
第二部分转到AI,从药物设计、药物相互作用预测写到安全性预测。后半段再把多组学与AI合并,观察它们在神经系统疾病、肿瘤、心血管疾病以及临床试验中的应用。
这个顺序解决了交叉综述最麻烦的一件事:同一种技术可能在多个环节出现。作者允许算法分散出现,每次只讨论它在当前研发任务里承担的工作。
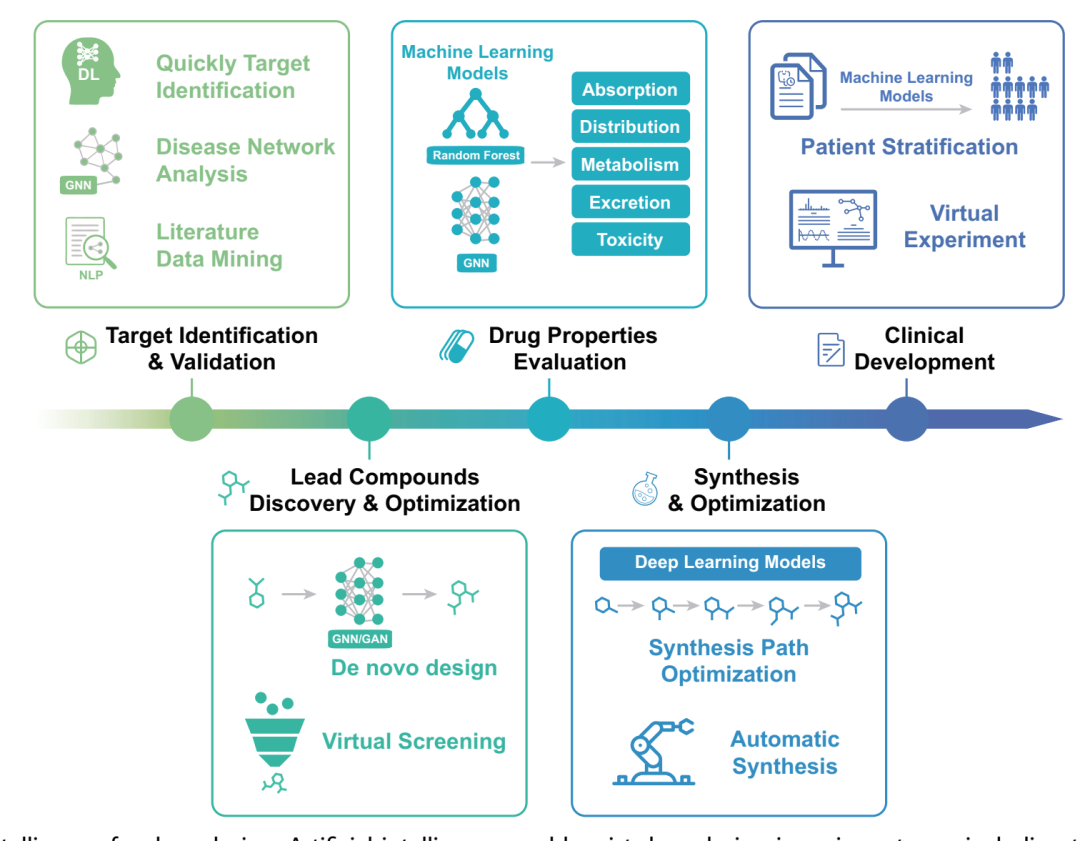
图2(原文Figure 2):这张图相当于AI部分的目录。上方是各阶段任务,下方放入对应方法,读者不需要先掌握算法谱系,也能找到它们在研发流程中的位置。
写同类综述时,可以先做一张二维矩阵。行是研发阶段,列是数据来源、分析方法、验证方式和临床状态。每篇纳入文献只放进一个主要位置,重复内容会立刻暴露出来。
这篇论文的7幅图都在回答“流程怎么走”。
Figure 1定义多组学的应用边界;Figure 2展示AI进入药物设计的环节;Figure 3拆分药代和药效相关的药物相互作用;Figure 4从临床前写到上市后的药物安全;Figure 5按疾病系统归纳案例;Figure 6覆盖临床试验设计、启动、实施和结题;Figure 7把数据、模型和研发输出收回一张总图。
8张表则负责回答“有哪些证据”。表格分别整理靶点发现、药物重定位、原创新化合物、药物相互作用、安全性预测、神经系统药物、抗肿瘤药物和临床试验设计案例。
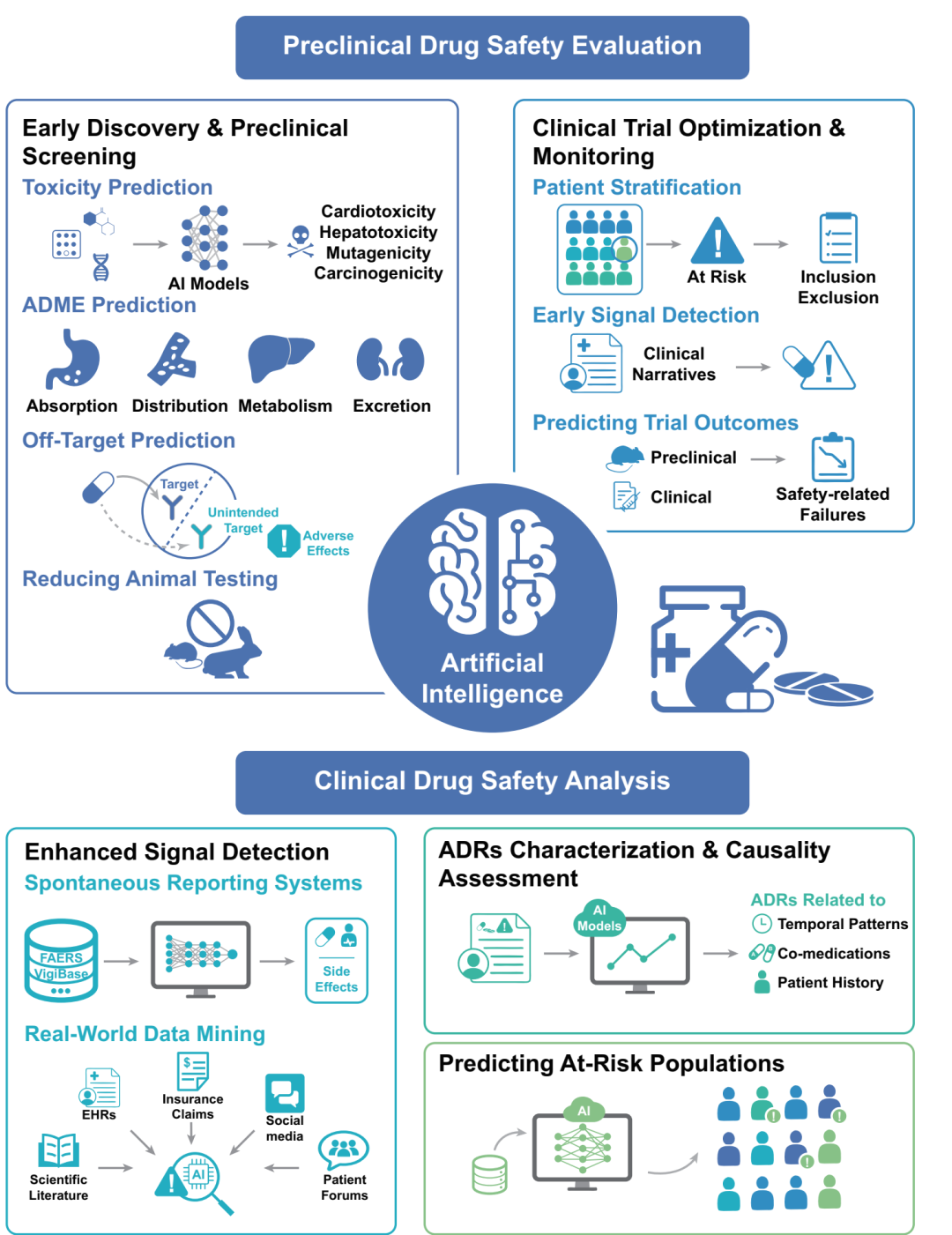
图3(原文Figure 4):安全性部分没有只谈毒性分类模型,还纳入患者分层、早期信号识别、真实世界数据和高风险人群预测。
这种分工很好用:图画关系,表放证据。
图里塞满药名、样本量和性能指标,手机端基本无法阅读。正文反复描述流程,读者又会觉得啰嗦。让图表各自承担一种任务,篇幅反而更省。
作者选了神经系统疾病、肿瘤和心血管疾病作为主要临床场景,还补充了部分罕见病案例。
这些疾病有一个共同点:病理异质性高,单一分子指标通常难以覆盖患者差异。多组学提供分层,AI完成跨模态整合和候选排序,选例逻辑与文章主线是吻合的。
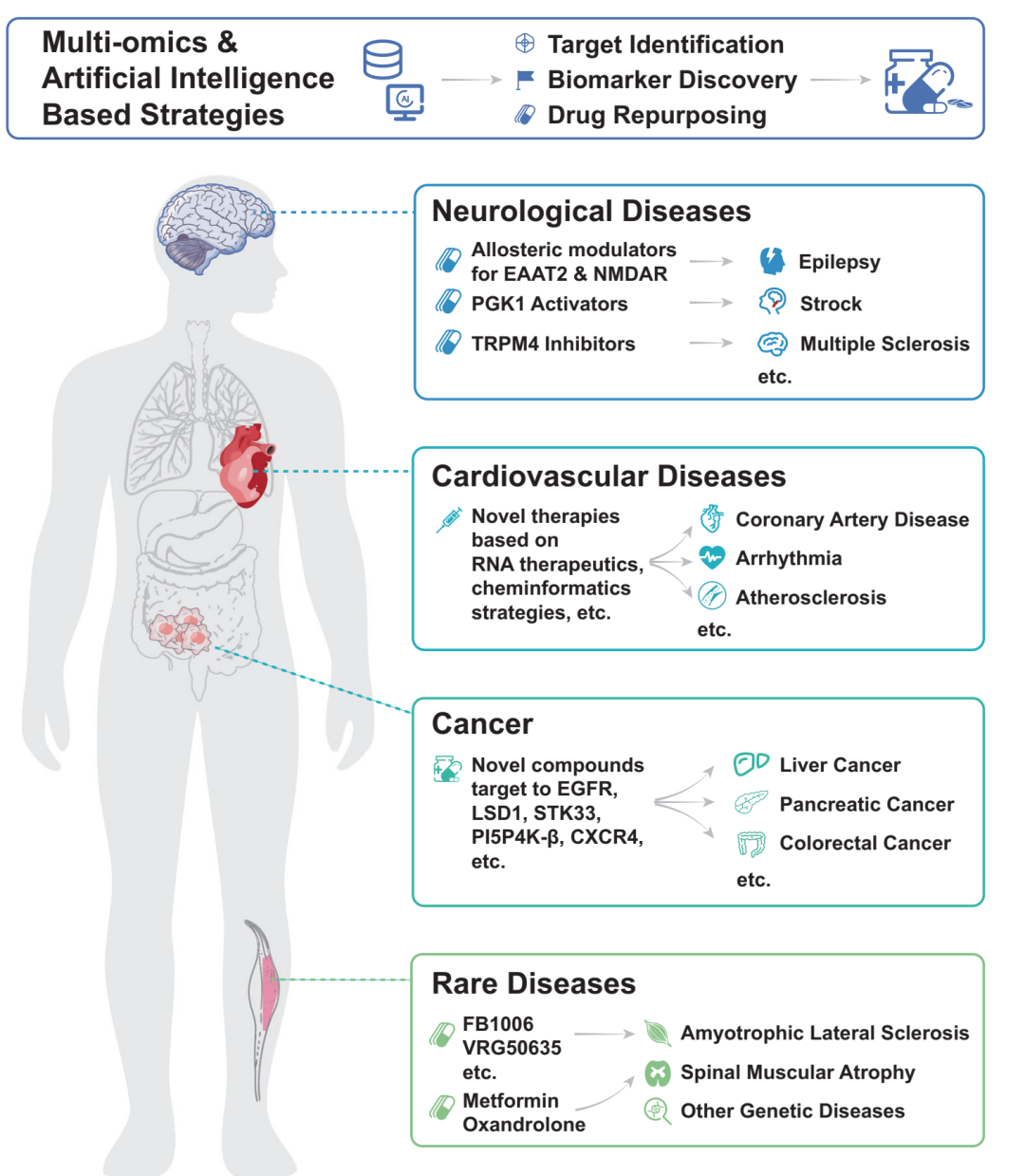
图4(原文Figure 5):这张图用于横向展示疾病领域。它适合回答“方法用到了哪里”,不适合比较各疾病领域的证据强弱。
病例数量多不等于论证更强。每个疾病方向挑两三类能说明机制、验证和转化阶段的代表性工作,通常比连续罗列十几个模型名称更有效。
这篇文章后半段仍有部分段落偏长,个别案例之间更像并列摘录。若准备写同类综述,可以在每个疾病小节固定保留三类内容:疾病中的具体难题、技术怎样处理这个难题、目前最可靠的验证到了哪一级。
文章往前走了一步,穿插了不少带数字的案例,用来检验“AI可以缩短研发周期”这类宽泛判断。
例如,作者介绍了用于特发性肺纤维化的TNIK抑制剂INS018_055。按照原文引用的资料,该项目从靶点识别推进至Ⅰ期临床评价用了18个月。
在单细胞基础模型部分,文章提到scGPT使用约3300万个正常人细胞转录组训练,覆盖51种器官或组织、441项独立研究。这类数字能说明训练数据规模,却不能单独证明药物已经产生临床获益。
临床试验部分还引用了2024年的行业资料:8家公司共有31个AI衍生候选药进入人体试验,其中17个仍在Ⅰ期,5个处于Ⅰ/Ⅱ期,9个进入Ⅱ/Ⅲ期;其间已有项目终止、停止或得到不确定结果。
把这组信息与“18个月进入Ⅰ期”放在一起,文章才没有只讲速度。进入临床是进展,获得稳定疗效和安全性证据是另一道门槛。
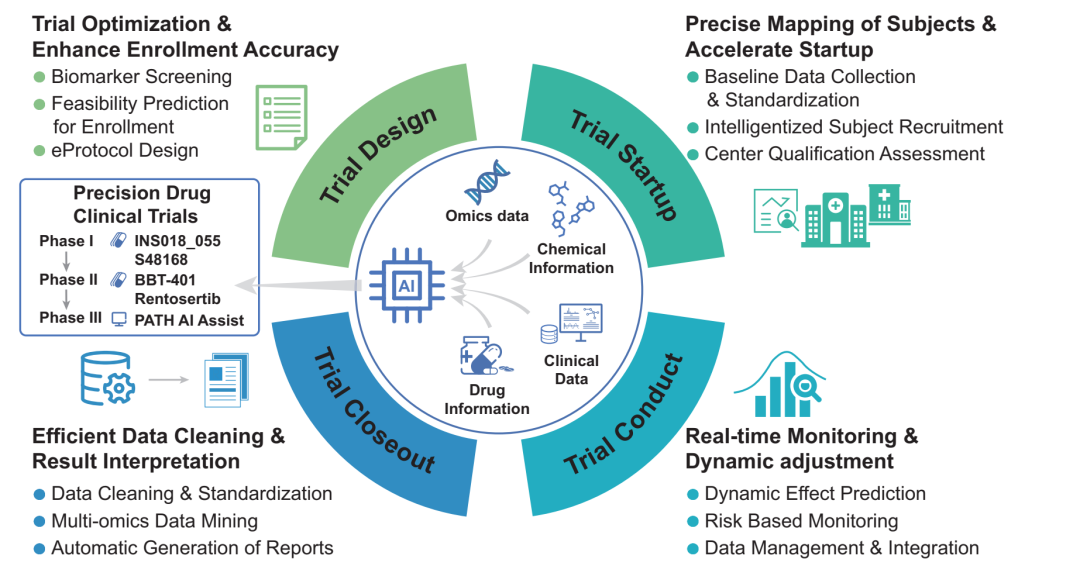
图5(原文Figure 6):作者把临床试验拆成四个阶段。左侧列出的候选项目能提供转化感,但项目所处期别会随时间变化,投稿前需要逐项更新。
写案例时,建议在笔记里给每条证据贴上阶段标签:计算预测、体外验证、动物验证、早期临床、关键性临床试验、监管批准、真实世界应用。
同一段可以放不同阶段的研究,但不能用早期数据替代临床结局。技术综述最容易失真的地方,往往就发生在这一步。
结论部分把多组学与AI带来的变化概括为几个方向:从单靶点转向网络药理,从线性研发转向计算与实验迭代,从人群平均方案转向患者层面的治疗预测。
作者也列出了数据标准不一致、缺失值与批次效应、模型黑箱、监管接受度、群体代表性不足、隐私保护和算法偏倚等障碍。
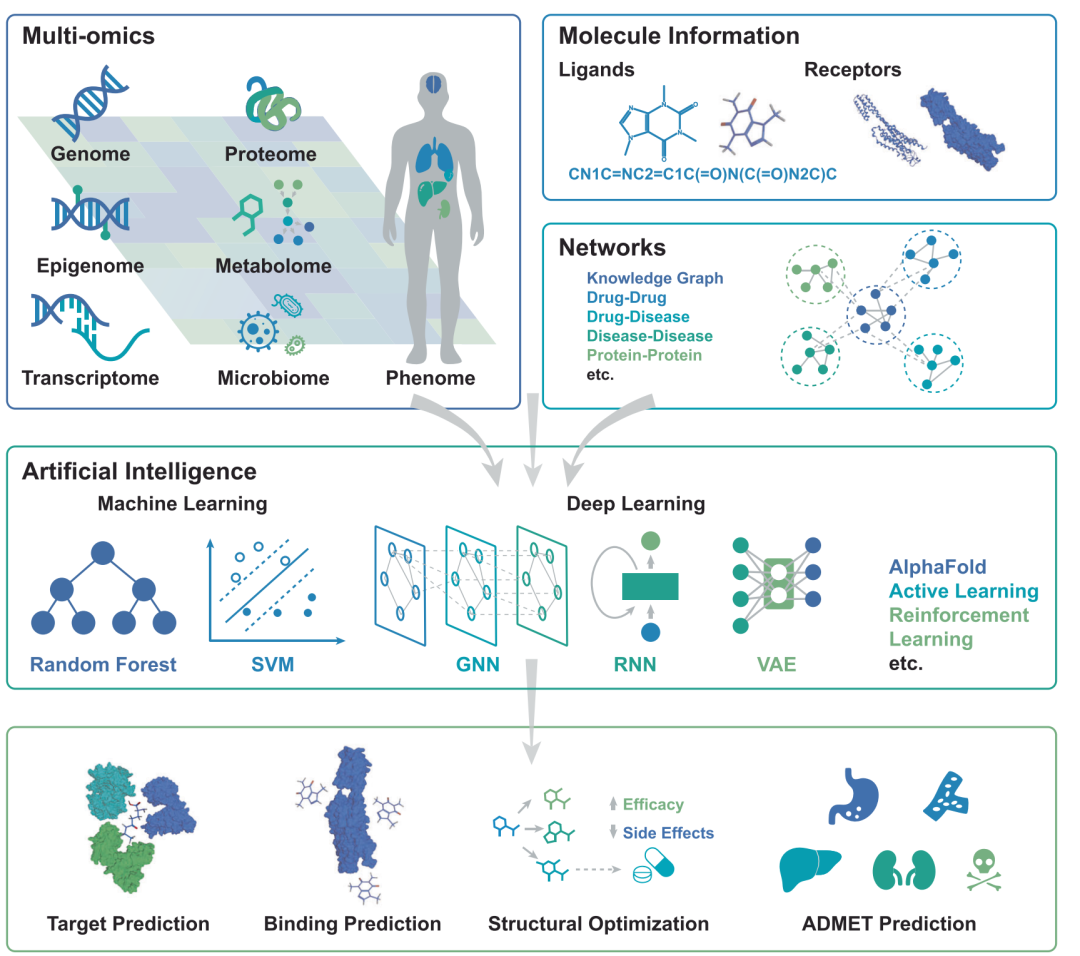
图6(原文Figure 7):全文收束图把输入、模型和输出连在一起。它也提醒作者在讨论中分别检查三处风险:数据是否可靠,模型是否可解释,输出是否经过临床相关验证。
这里有一个很实用的写法:讨论局限时,不要另起一份通用问题清单。沿着自己的流程图倒着检查就行。
数据层看标准化、缺失和人群代表性;模型层看外部验证、可解释性和可迁移性;实验层看体外模型与人体病理是否接近;临床层看终点、监管要求和公平性。
局限一旦能对应到流程节点,讨论才会和全文发生关系。
作者在“Literature-search strategy”中将文章称为系统性文献综述,并说明检索了PubMed、Web of Science和Scopus,使用MeSH扩展与布尔逻辑。
不过,从PDF正文能看到的信息看,作者没有报告完整检索式、检索日期、纳入与排除标准、筛选数量、流程图、质量评价或偏倚评估。
因此,更稳妥的理解是:这是一篇采用结构化检索的综合性叙述综述。检索过程提高了覆盖面,现有报告还不足以让读者完整复现筛选过程。
准备投稿时,文章类型要尽早确定。
如果目标是系统综述,就按相应报告规范保存检索式、筛选记录和质量评价。如果目标是大型叙述综述,仍可以透明报告数据库、时间范围和选文原则,但不必为了显得严谨而使用超出方法证据的标签。
另一个问题是证据更新。药物研发期别、临床试验状态和公司合作变化很快。综述从投稿到发表常常要经历数月,定稿前至少要重新核对试验注册平台、监管状态和企业公告日期。
第一步,写出范围句。
用一句话限定对象、技术、研发阶段和临床场景。范围句写不清,后面的检索词一定会膨胀。
第二步,先搭证据矩阵。
横向放研发环节,纵向记录研究问题、数据类型、算法、验证层级、主要结果和局限。先填矩阵,再决定章节。
第三步,为每节准备“框架—案例—边界”。
框架解释方法如何工作;案例给出药物、数据或性能数字;边界说明证据尚未覆盖哪里。三部分不必等长,但不能长期缺席其中一项。
第四步,提前规划图表。
总览图负责划范围,流程图负责讲机制,疾病图负责展示应用,收束图负责讨论输入、模型和输出。表格按证据任务分组,不按作者或年份简单堆叠。
第五步,给案例标注验证层级和更新时间。
计算命中、动物有效、进入Ⅰ期、获批上市,含义相差很大。涉及在研药物时,在资料表中单列“状态核对日期”。
第六步,最后写引言和讨论。
正文证据整理完成后,再回头决定引言该提出什么缺口,讨论该回应哪些限制。这样写出的首尾更贴近文章实际内容。
这篇综述的长处在于结构控制。作者用药物研发流程约束了一个很宽的交叉主题,再用7幅流程图和8张证据表降低阅读负担。案例横跨机制、模型和临床阶段,文章因此保持了转化方向。
它也提醒我们,覆盖面和证据强度不能混为一谈。算法名、数据规模和候选药数量可以证明领域活跃,临床价值仍要看外部验证、试验终点、监管状态和真实患者获益。
如果准备写一篇同类论文,最先该画的是一张带验证层级的研发流程表。那张表能不能站住,基本决定了综述能否从资料汇编走向有依据的判断。
原文来源
Liu Y, Zhu K, Peng W, Liu Z, Mao X. Multi-omics and artificial intelligence for precision drug discovery and potential clinical applications. Signal Transduction and Targeted Therapy. 2026;11:210. doi:10.1038/s41392-026-02631-6.
说明:文中数据和研发案例均据原论文及其引用资料整理;在研项目状态具有时效性,不构成临床用药建议。配图均截取自原论文。
PAPER INFORMATION

快速预审、投刊前指导、专业学术评审,对文章进行评价

校对编辑、深度润色,让稿 件符合学术规范,格式体例等标准
.png)
适用于语句和结构尚需完善和调整的中文文章,确保稿件达到要求
.png)
数据库包括: 期刊、文书籍、会议、预印章、书、百科全书和摘要等
让作者在期刊选择时避免走弯路,缩短稿件被接收的周期
根据目标期刊格式要求对作者文章进行全面的格式修改和调整
帮助作者将稿件提交至目标期刊投稿系统,降低退稿或拒稿率
按照您提供的稿件内容,指导完成投稿附信(cover letter)







北京总部:北京市海淀区碧桐园 3 号楼 2 层 211 广州办事处:广州市黄埔区科学城国际企业孵化器 E栋306 联系人:客服 / 18163670350
Copyright © 2022-2024 北京特诺科技有限公司 版权所有 备案/许可证编号为: 京 ICP 备 2023007944 号
