
来源:特诺科研
心血管疾病是全球头号死因,2022 年致死量达 1980 万例,人口老龄化背景下发病数还在持续攀升,早筛早诊成为降低疾病负担的关键。但传统风险分层模型依赖临床指标,预测效能有限,多组学技术的临床转化还存在诸多瓶颈。近日,天津医科大学第二医院联合香港城市大学、香港大学等团队在《Nature Communications》(IF=15.7,综合领域顶刊,0 版面费开源获取)发表重磅研究:依托英国生物银行大样本队列,开发AI 驱动的 CardiOmicScore 多组学分析框架,整合基因组、代谢组、蛋白质组多维度数据,首次构建 6 大类心血管病的疾病特异性风险评分(MetScore/ProScore),实现疾病提前 15 年的个性化精准预测,联合临床数据可将预测 C-index 提升 0.005~0.102,还筛选出核心生物标志物并阐明不同组学的互补作用!

文章信息速览
原标题:AI-based multiomics profiling reveals complementary omics contributions to personalized prediction of cardiovascular disease
期刊:Nature Communications(IF=15.7)
关键词:心血管疾病、多组学、人工智能、基因组、代谢组、蛋白质组、CardiOmicScore、MetScore、ProScore、个性化风险预测、生物标志物、脂蛋白代谢
研究背景与临床痛点
疾病负担沉重:心血管病是全球首位致死病因,2022 年约 1980 万人因此离世,人口老龄化趋势下发病率持续升高,早期精准风险分层成为疾病防控的核心需求;
传统模型局限:ASCVD、SCORE2 等经典风险预测模型仅依赖常规临床危险因素,区分度和校准度不足;整合多基因风险评分(PRS)也仅小幅提升预测效能,无法捕捉疾病背后的病理生理过程;
技术转化瓶颈:代谢组、蛋白质组为无创风险预测提供了新方向,但缺乏多组学整合的纵向队列数据,且现有计算框架无法处理组学数据的高维非线性关联,难以实现规模化应用;
研究存在空白:既往多组学研究仅聚焦心肌梗死、房颤等少数心血管病,未阐明代谢组和蛋白质组在全谱心血管病中的互补调控作用,也缺乏针对性的疾病特异性风险评分工具。
研究核心亮点
这篇顶刊多组学研究的成功,核心在于遵循“临床痛点切入→多队列严谨设计→AI 模型构建→多维度验证→生物标志物挖掘”的顶刊发文逻辑,5 大研究步骤层层递进,关键图表直观支撑结论,更是为临床医生开展多组学研究、冲刺高 IF 顶刊提供了可复刻的经典范例:
第一步:分层队列设计,夯实大样本数据基础,契合顶刊数据严谨性要求(图 1)
核心研究:基于英国生物银行队列,先排除无组学数据的受试者,再按组学类型分为代谢组单独队列(220,859 例)、蛋白质组单独队列(19,086 例)、多组学独立验证队列(24,287 例);同时将前两个队列进一步拆分为训练 / 验证集(英格兰、威尔士)和地理测试集(苏格兰),用于评估模型的区域外推性(图 1)。基线特征:各队列受试者中位年龄 56~58 岁,男性占比 42.8%~45.8%,基线用药、疾病发病情况分布一致,保证了研究的可比性。医生发文技巧:多组学研究想要冲刺顶刊,需注重队列的分层设计和独立验证,增设地理测试集能显著提升模型的外推性,契合顶刊对研究数据严谨性的核心要求。
第二步:搭建 AI 多任务框架,构建疾病特异性多组学风险评分,打造顶刊技术亮点(图 1)
核心研究:针对组学数据的高维特性,摒弃传统线性回归,开发MetNet 和 ProNet 多任务深度学习模型,分别对 168 种代谢物、2920 种蛋白质进行分析,首次生成 6 大类心血管病(冠心病、卒中、心衰、房颤、外周动脉病、静脉血栓栓塞)的疾病特异性代谢组风险评分(MetScore)和蛋白质组风险评分(ProScore)(图 1)。医生发文技巧:面对组学数据的高维、非线性关联特点,采用 AI 多任务模型替代传统统计方法,能更精准捕捉数据间的复杂关系,是多组学研究发表顶刊的核心技术亮点,也是提升文章创新性的关键。
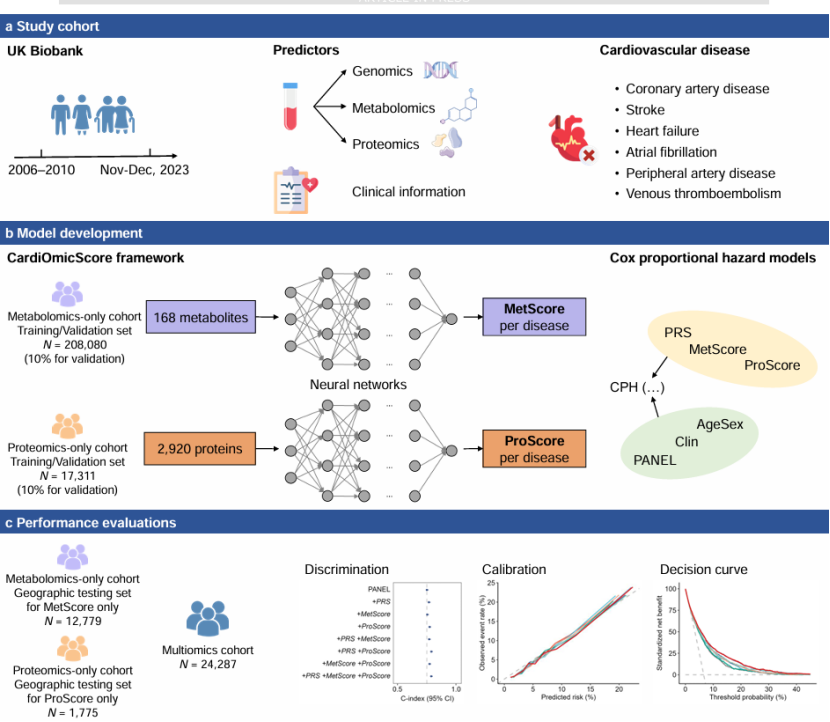
图1
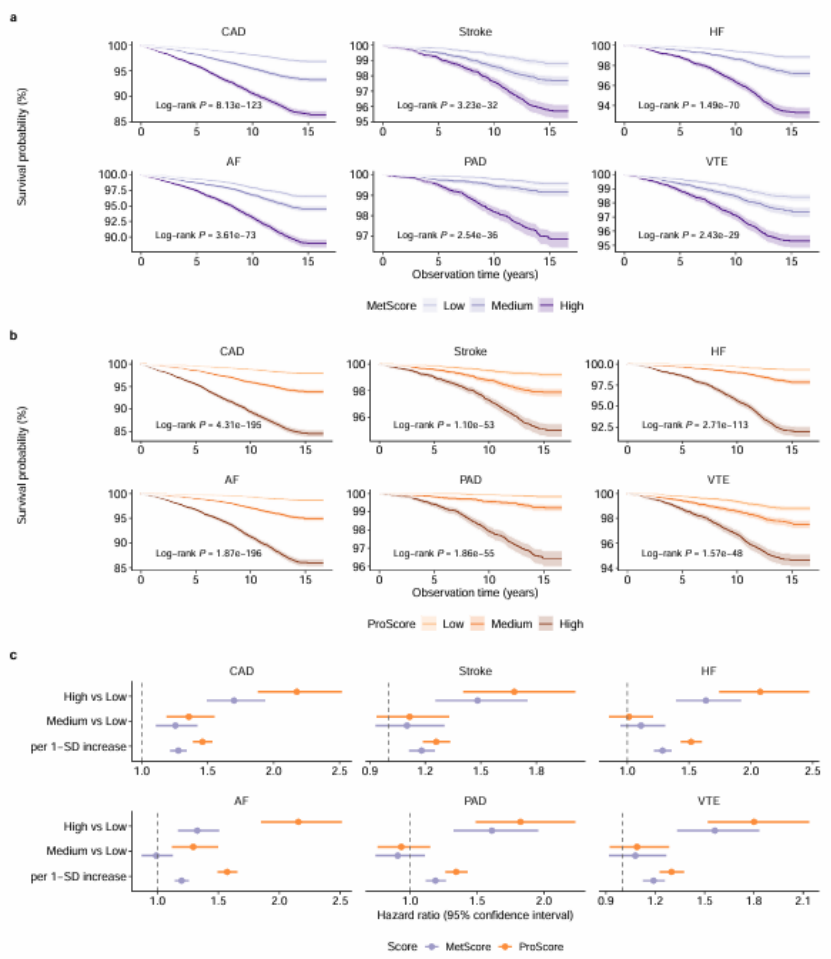
图2
第三步:多指标验证,证实多组学评分的强独立预测效能,夯实顶刊研究结论(图 3、生存曲线)
核心研究:通过 Harrell’s C-index 验证发现,MetScore 和 ProScore 均为心血管病的强独立预测因子,MetScore 的 C-index 达 0.64~0.74,ProScore 的 C-index 达 0.69~0.82;将其与临床数据结合后,可使 6 大类心血管病的预测 C-index 提升 0.005~0.102,且能实现提前 15 年的精准风险预测(图 3)。生存曲线分析显示,MetScore/ProScore 高分组受试者的心血管病发病风险显著升高,Log-rank P 值均低至 1e-29 以下,进一步证实了多组学评分的预测效能(生存曲线 a/b)。医生发文技巧:多组学评分的预测效能需通过C-index、生存分析、风险比等多指标进行验证,结合长期随访数据体现临床价值,是顶刊评审重点关注的研究结论支撑。
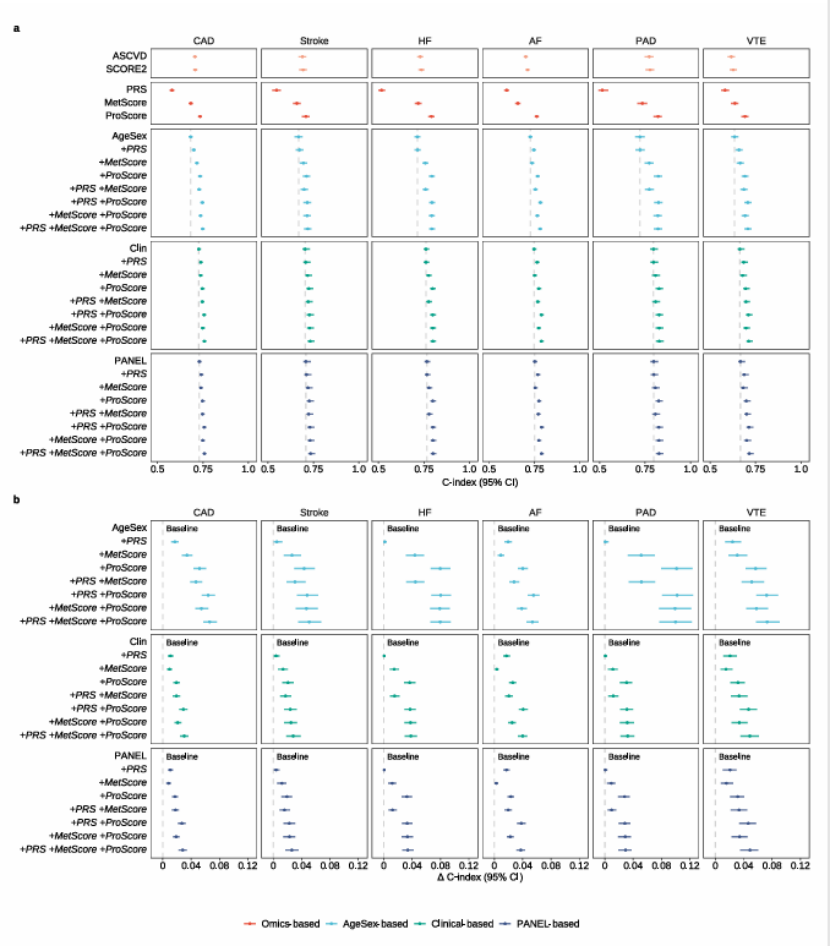
图3
第四步:临床效用验证,证实模型的实际转化价值,贴合顶刊临床导向需求(图 4)
核心研究:校准曲线显示,整合多组学信息的 Cox 比例风险模型,其预测风险与实际事件发生率高度吻合,模型校准度优异(图 4a);净获益曲线分析发现,多组学整合模型的临床净获益显著高于单纯临床模型,且阈值概率范围广,具有明确的实际临床应用价值(图 4b)。医生发文技巧:顶刊不仅关注模型的预测效能,更看重临床实际转化价值,通过校准曲线和决策曲线(净获益曲线)验证模型的临床效用,能让研究结论更贴合临床需求,大幅提升文章的顶刊录用概率。
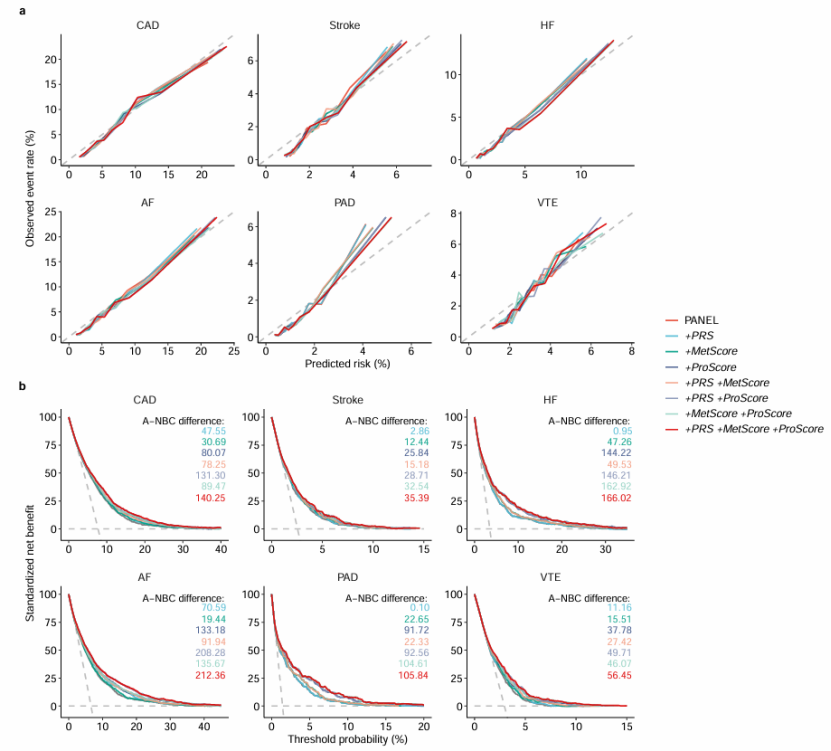
图4
第五步:挖掘核心生物标志物,阐明组学互补作用,增加顶刊研究深度(图 5、6)
核心研究:通过 SHAP 值分析,筛选出 6 大类心血管病的65 种核心代谢物和 77 种核心蛋白(图 5);进一步分析发现,代谢组主要参与脂蛋白代谢,蛋白质组则聚焦凝血、炎症、氧化应激和血管重构过程,明确了代谢组和蛋白质组在心血管病风险预测中的互补作用(图 6)。医生发文技巧:多组学研究不能仅停留在模型构建层面,需从高维组学数据中挖掘核心生物标志物,并阐明不同组学的互补调控机制,让研究既有技术层面的创新,又有机制层面的深度,是顶刊研究的核心加分项。
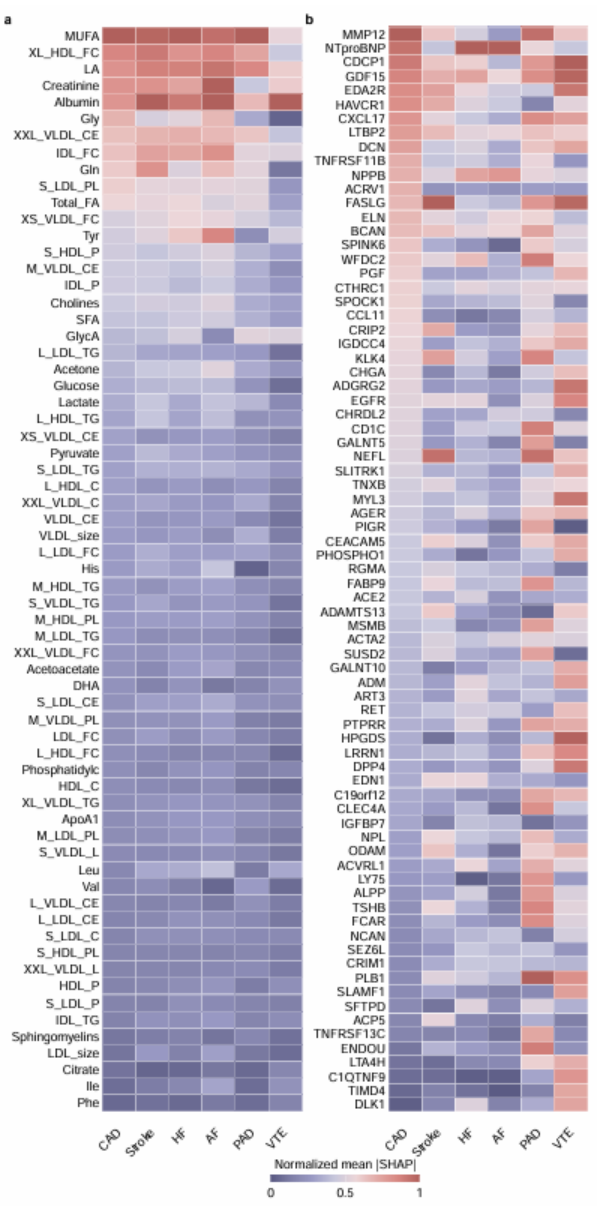
图5
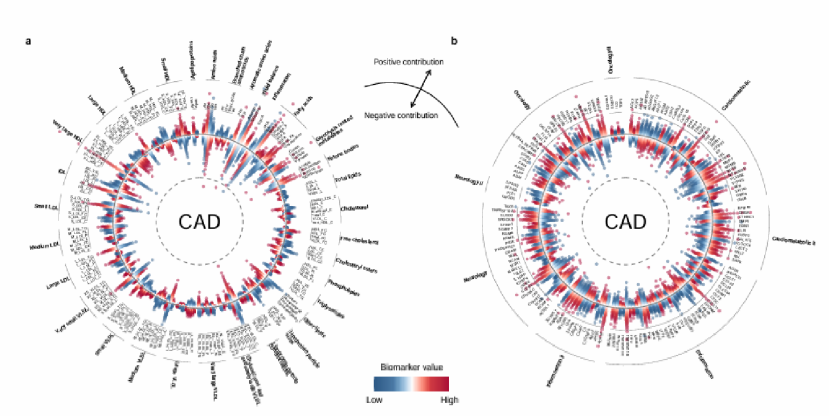
图6
总结:多组学顶刊发文的核心逻辑,解锁心血管病精准早筛新策略
天津医科大学第二医院联合香港城市大学、香港大学等团队,以心血管病早期精准筛查的临床痛点为切入点,依托英国生物银行大样本队列,遵循“临床需求→数据设计→AI 建模→多维度验证→机制挖掘”的顶刊多组学发文逻辑,开发了AI 驱动的 CardiOmicScore 多组学分析框架,首次构建了 6 大类心血管病的疾病特异性代谢组 / 蛋白质组风险评分,证实多组学数据与临床数据的整合可显著提升心血管病的早筛效能,实现提前 15 年的个性化风险预测,还筛选出核心生物标志物并阐明了代谢组和蛋白质组的互补作用,为心血管病的精准预防和生物标志物开发提供了全新思路。
该研究的整体设计和实施,为临床医生开展多组学研究、冲刺高 IF 顶刊提供了可直接复刻的经典范例,也为心血管病的精准防控提供了兼具临床价值和应用前景的新工具。
原文DOI: 10.1038/s41467-026-68956-6
专注期刊投稿、发表十年,任何投稿、写作难题欢迎咨询!

PAPER INFORMATION

快速预审、投刊前指导、专业学术评审,对文章进行评价

校对编辑、深度润色,让稿 件符合学术规范,格式体例等标准
.png)
适用于语句和结构尚需完善和调整的中文文章,确保稿件达到要求
.png)
数据库包括: 期刊、文书籍、会议、预印章、书、百科全书和摘要等
让作者在期刊选择时避免走弯路,缩短稿件被接收的周期
根据目标期刊格式要求对作者文章进行全面的格式修改和调整
帮助作者将稿件提交至目标期刊投稿系统,降低退稿或拒稿率
按照您提供的稿件内容,指导完成投稿附信(cover letter)







北京总部:北京市海淀区碧桐园 3 号楼 2 层 211 广州办事处:广州市黄埔区科学城国际企业孵化器 E栋306 联系人:客服 / 18163670350
Copyright © 2022-2024 北京特诺科技有限公司 版权所有 备案/许可证编号为: 京 ICP 备 2023007944 号
